場景:現在有一個錯詞庫,維護的是錯詞和正確詞對應關係。比如:錯詞“我門”對應的正確詞“我們”。然後在用戶輸入的文字進行錯詞校驗,需要判斷輸入的文字是否有錯詞,並找出錯詞以便提醒用戶,並且可以顯示出正確詞以便用戶確認,如果是錯詞就進行替換。
首先想到的就是取出錯詞List放在內存中,當用戶輸入完成後用錯詞List來foreach每個錯詞,然後查找輸入的字符串中是否包含錯詞。這是一種有效的方法,並且能夠實現。問題是錯詞的數量比較多,目前有10多萬條,將來也會不斷更新擴展。所以pass了這種方案,為了讓錯詞查找提高速度就用了字典樹來存儲錯詞。
字典樹
Trie樹,即字典樹,又稱單詞查找樹或鍵樹,是一種樹形結構,是一種哈希樹的變種。典型應用是用於統計和排序大量的字符串(但不僅限於字符串),所以經常被搜索引擎系統用於文本詞頻統計。它的優點是:最大限度地減少無謂的字符串比較。
Trie的核心思想是空間換時間。利用字符串的公共前綴來降低查詢時間的開銷以達到提高效率的目的。
通常字典樹的查詢時間複雜度是O(logL),L是字符串的長度。所以效率還是比較高的。而我們上面說的foreach循環則時間複雜度為O(n),根據時間複雜度來看,字典樹效率應該是可行方案。
字典樹原理
根節點不包含字符,除根節點外每一個節點都只包含一個字符; 從根節點到某一節點,路徑上經過的字符連接起來,為該節點對應的字符串; 每個節點的所有子節點包含的字符都不相同。
比如現在有錯詞:“我門”、“旱睡”、“旱起”。那麼字典樹如下圖
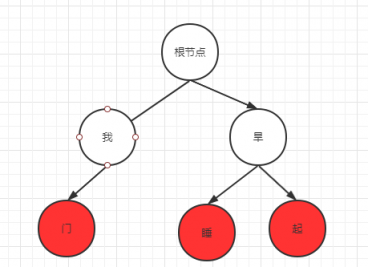
其中紅色的點就表示詞結束節點,也就是從根節點往下連接成我們的詞。
實現字典樹:
public class Trie { private class Node { ////// 是否單詞根節點 ///public bool isTail = false; public DictionarynextNode; public Node(bool isTail) { this.isTail = isTail; this.nextNode = new Dictionary(); } public Node() : this(false) { } } ////// 根節點 ///private Node rootNode; private int size; private int maxLength; public Trie() { this.rootNode = new Node(); this.size = 0; this.maxLength = 0; } ////// 字典樹中存儲的單詞的最大長度 //////public int MaxLength() { return maxLength; } ////// 字典樹中存儲的單詞數量 ///public int Size() { return size; } ////// 獲取字典樹中所有的詞 ///public ListGetWordList() { return GetStrList(this.rootNode); } private ListGetStrList(Node node) { ListwordList = new List(); foreach (char nextChar in node.nextNode.Keys) { string firstWord = Convert.ToString(nextChar); Node childNode = node.nextNode[nextChar]; if (childNode == null || childNode.nextNode.Count == 0) { wordList.Add(firstWord); } else { if (childNode.isTail) { wordList.Add(firstWord); } ListsubWordList = GetStrList(childNode); foreach (string subWord in subWordList) { wordList.Add(firstWord + subWord); } } } return wordList; } ////// 向字典中添加新的單詞 //////public void Add(string word) { //從根節點開始 Node cur = this.rootNode; //循環遍歷單詞 foreach (char c in word.ToCharArray()) { //如果字典樹節點中沒有這個字母,則添加 if (!cur.nextNode.ContainsKey(c)) { cur.nextNode.Add(c, new Node()); } cur = cur.nextNode[c]; } cur.isTail = true; if (word.Length > this.maxLength) { this.maxLength = word.Length; } size++; } ////// 查詢字典中某單詞是否存在 /////////public bool Contains(string word) { return Match(rootNode, word); } ////// 查找匹配 ////////////private bool Match(Node node, string word) { if (word.Length == 0) { if (node.isTail) { return true; } else { return false; } } else { char firstChar = word.ElementAt(0); if (!node.nextNode.ContainsKey(firstChar)) { return false; } else { Node childNode = node.nextNode[firstChar]; return Match(childNode, word.Substring(1, word.Length - 1)); } } } }
測試下:
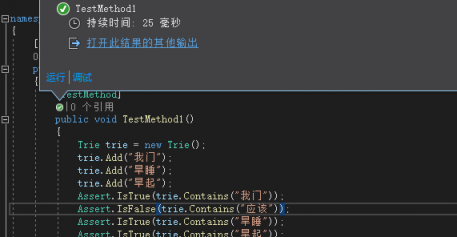
現在我們有了字典樹,然後就不能以字典樹來foreach,字典樹用於檢索。我們就以用戶輸入的字符串為數據源,去字典樹種查找是否存在錯詞。因此需要對輸入字符串進行取詞檢索。也就是分詞,分詞我們採用前向最大匹配。
前向最大匹配
我們分詞的目的是將輸入字符串分成若干個詞語,前向最大匹配就是從前向後尋找在詞典中存在的詞。
例子:我們假設maxLength= 3,即假設單詞的最大長度為3。實際上我們應該以字典樹中的最大單詞長度,作為最大長度來分詞(上面我們的字典最大長度應該是2)。這樣效率更高,為了演示匹配過程就假設maxLength為3,這樣演示的更清楚。
用前向最大匹配來劃分“我們應該早睡早起” 這句話。因為我是錯詞匹配,所以這句話我改成“我門應該旱睡旱起”。
第一次:取子串 “我門應”,正向取詞,如果匹配失敗,每次去掉匹配字段最後面的一個字。
“我門應”,掃描詞典中單詞,沒有匹配,子串長度減 1 變為“我門”。
“我門”,掃描詞典中的單詞,匹配成功,得到“我門”錯詞,輸入變為“應該旱”。
第二次:取子串“應該旱”
“應該旱”,掃描詞典中單詞,沒有匹配,子串長度減 1 變為“應該”。
“應該”,掃描詞典中的單詞,沒有匹配,輸入變為“應”。
“應”,掃描詞典中的單詞,沒有匹配,輸入變為“該旱睡”。
第三次:取子串“該旱睡”
“該旱睡”,掃描詞典中單詞,沒有匹配,子串長度減 1 變為“該旱”。
“該旱”,掃描詞典中的單詞,沒有匹配,輸入變為“該”。
“該”,掃描詞典中的單詞,沒有匹配,輸入變為“旱睡旱”。
第四次:取子串“旱睡旱”
“旱睡旱”,掃描詞典中單詞,沒有匹配,子串長度減 1 變為“旱睡”。
“旱睡”,掃描詞典中的單詞,匹配成功,得到“旱睡”錯詞,輸入變為“早起”。
以此類推,我們得到錯詞 我們/旱睡/旱起。
因為我是結合字典樹匹配錯詞所以一個字也可能是錯字,則匹配到單個字,如果只是分詞則上面的到一個字的時候就應該停止分詞了,直接字符串長度減1。
這種匹配方式還有後向最大匹配以及雙向匹配,這個大家可以去了解下。
實現前向最大匹配,這裡後向最大匹配也可以一起實現。
public class ErrorWordMatch { private static ErrorWordMatch singleton = new ErrorWordMatch(); private static Trie trie = new Trie(); private ErrorWordMatch() { } public static ErrorWordMatch Singleton() { return singleton; } public void LoadTrieData(ListerrorWords) { foreach (var errorWord in errorWords) { trie.Add(errorWord); } } ////// 最大 正向/逆向 匹配錯詞 //////需要匹配錯詞的字符串///true為從左到右分詞,false為從右到左分詞///匹配到的錯詞public ListMatchErrorWord(string inputStr, bool leftToRight) { if (string.IsNullOrWhiteSpace(inputStr)) return null; if (trie.Size() == 0) { throw new ArgumentException("字典樹沒有數據,請先調用 LoadTrieData 方法裝載字典樹"); } //取詞的最大長度 int maxLength = trie.MaxLength(); //取詞的當前長度 int wordLength = maxLength; //分詞操作中,處於字符串中的當前位置 int position = 0; //分詞操作中,已經處理的字符串總長度 int segLength = 0; //用於嘗試分詞的取詞字符串 string word = ""; //用於儲存正向分詞的字符串數組 ListsegWords = new List(); //用於儲存逆向分詞的字符串數組 ListsegWordsReverse = new List(); //開始分詞,循環以下操作,直到全部完成 while (segLength < inputStr.Length) { //如果剩餘沒分詞的字符串長度<取詞的最大長度,則取詞長度等於剩餘未分詞長度 if ((inputStr.Length - segLength) < maxLength) wordLength = inputStr.Length - segLength; //否則,按最大長度處理 else wordLength = maxLength; //從左到右 和 從右到左截取時,起始位置不同 //剛開始,截取位置是字符串兩頭,隨著不斷循環分詞,截取位置會不斷推進 if (leftToRight) position = segLength; else position = inputStr.Length - segLength - wordLength; //按照指定長度,從字符串截取一個詞 word = inputStr.Substring(position, wordLength); //在字典中查找,是否存在這樣一個詞 //如果不包含,就減少一個字符,再次在字典中查找 //如此循環,直到只剩下一個字為止 while (!trie.Contains(word)) { //如果最後一個字都沒有匹配,則把word設置為空,用來表示沒有匹配項(如果是分詞直接break) if (word.Length == 1) { word = null; break; } //把截取的字符串,最邊上的一個字去掉 //從左到右 和 從右到左時,截掉的字符的位置不同 if (leftToRight) word = word.Substring(0, word.Length - 1); else word = word.Substring(1); } //將分出匹配上的詞,加入到分詞字符串數組中,正向和逆向不同 if (word != null) { if (leftToRight) segWords.Add(word); else segWordsReverse.Add(word); //已經完成分詞的字符串長度,要相應增加 segLength += word.Length; } else { //沒匹配上的則+1,丟掉一個字(如果是分詞 則不用判斷word是否為空,單個字也返回) segLength += 1; } } //如果是逆向分詞,對分詞結果反轉排序 if (!leftToRight) { for (int i = segWordsReverse.Count - 1; i >= 0; i--) { //將反轉的結果,保存在正向分詞數組中 以便最後return 同一個變量segWords segWords.Add(segWordsReverse[i]); } } return segWords; } }
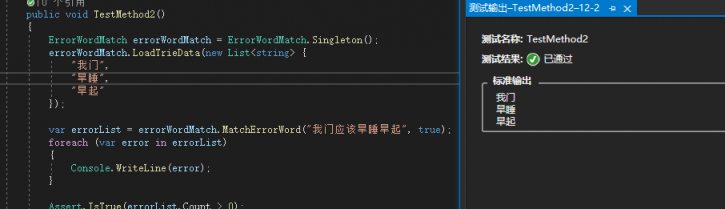
這裡使用了單例模式用來在項目中共用,在第一次裝入了字典樹後就可以在其他地方匹配錯詞使用了。
這個是結合我具體使用,簡化了些代碼,如果只是分詞的話就是分詞那個實現方法就行了。最後分享就到這裡吧,如有不對之處,請加以指正。
[limiyoyo ] C#實現前向最大匹、字典樹(分詞、檢索)的示例代碼已經有243次圍觀
