我將試圖以從無到有的過程來粗淺的解釋文件系統是如何運作的,也就是從得到一個分區到在這個文件系統上進行各種操作的過程。
可以通過這種方式得到一個塊文件,而把它當作一個分區來使用:
# cd /tmp/
# touch syda
# dd if=/dev/null of=syda count=0 seek=500000
# losetup /dev/loop0 syda
這樣子,就可以把環設備loop0看作是一個硬碟的分區了。
得到一個分區,首先要對它進行格式化,之後操作系統才能使用這個分區。傳統的磁碟應用中,一個分區只能被格式化成一個文件系統,我們可以說一個文件系統就是一個分區。但由於新技術的利用,如今一個分區可以格式化為多個文件系統(LVM),也可以將將多個分區合成一個文件系統(LVM,RAID)。對於這些內容我無能力介紹。同時,本文只在Linux下ext3日誌文件系統類型下來認識文件系統。
對於文件系統來說,磁碟是由一個個「塊」(block)組成的。這些塊的大小是2的次方,目前支持的塊大小是1k、2k和4k三種。所有這些塊都被以自然序列編號[0-n ]。Ext3 文件系統將其所管理的分區中的塊劃分到不同的塊組中。每個塊組大小相同,當然最後一個塊組所管理的塊可能會少一些,其大小在文件系統創建時決定,主要取決於文件系統的塊大小,對於大小為4k的文件系統塊來說,塊組大小為 168M。這些塊組也被編上號group[0-n ]。其邏輯形式為:
[文件系統]=[塊組0|塊組1|塊組2|……|塊組n ]
[塊組k] =[超級塊|塊組描述表|塊點陣圖|inode點陣圖|inode表|數據域](k>=0)
每個塊組包含一個塊點陣圖塊,一個inode點陣圖塊,一個或多個塊用於描述inode表和用於存儲文件數據的數據塊,除此之外,還有可能包含超級塊和所有塊組描述符表(取決於塊組號和文件系統創建時使用的參數)。下面將對這些元數據作一些簡要介紹。
塊點陣圖用於描述該塊組所管理的塊的分配狀態。它的作用是標記已經使用了的塊。由於塊點陣圖僅佔一個塊,因此這也就決定了塊組的大小。
Inode點陣圖用於描述該塊組所管理的inode的分配狀態。由於其僅佔用一個塊,因此這也限制了一個塊組中所能夠使用的最大inode數量。
Inode表用於存儲inode信息。它佔用一個或多個塊(為了有效的利用空間,多個inode存儲在一個塊中),其大小取決於文件系統創建時的參數,由於inode點陣圖的限制,決定了其最大所佔用的空間。
超級塊用於存儲文件系統全局的配置參數(譬如:塊大小,總的塊數和inode數)和動態信息(譬如:當前空閑塊數和inode數),其處於文件系統開始位置的1k處,所佔大小為1k。為了系統的健壯性,最初每個塊組都有超級塊和組描述表(以下將用GDT)的一個拷貝,但是當文件系統很大時,這樣浪費了很多塊(尤其是GDT佔用的塊多),後來採用了一種稀疏的方式來存儲這些拷貝,只有塊組號是3, 5 ,7的冪的塊組(譬如說1,3,5,7,9,25,49…)才備份這個拷貝。通常情況下,只有主拷貝(第0塊塊組)的超級塊信息被文件系統使用,其它拷貝只有在主拷貝被破壞的情況下才使用。
GDT用於存儲塊組描述符,其佔用一個或者多個數據塊,具體取決於文件系統的大小。它主要包含塊點陣圖,inode點陣圖和inode表位置,當前空閑塊數,inode數以及使用的目錄數(用於平衡各個塊組目錄數)。每個塊組都對應這樣一個描述符,目前該結構佔用32個位元組,因此對於塊大小為4k的文件系統來說,每個塊可以存儲128個塊組描述符。由於GDT對於定位文件系統的元數據非常重要,因此和超級塊一樣,也對其進行了備份。GDT在每個塊組(如果有備份)中內容都是一樣的,其所佔塊數也是相同的。
下面我對剛才得到的分區進行格式化,格式化其實就是對上面所解釋的結構進行分配的過程。
# mkfs -t ext3 /dev/loop0
這條命令將/dev/loop0格式化成ext3類型的文件系統。下面通過命令dumpe2fs來查看超級塊與塊組描述中的內容。我將省略結果中的一些內容,因為太長了。
# dumpe2fs /dev/loop0
dumpe2fs 1.41.12 (17-May-2010)
Filesystem volume name:
<==文件系統名稱(Label)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype sparse_super
Filesystem state: clean <==文件系統是沒問題的(clean)
Filesystem OS type: Linux
Inode count: 62744 <==inode總數
Block count: 250000 <==塊總數
Free blocks: 235903 <==空閑塊數
Free inodes: 62733 <==空閑inode數
First block: 1 <==它沒從塊0開始,這裡0號塊被保留作特殊用途,這裡不贅述。
Block size: 1024 <==每個塊大小,1k
……
Inode size: 128 <==每個inode大小,128bytes
……
上面這些就是超級塊中紀錄的內容,下面是塊組描述記錄的內容,由於每個塊組都是一樣的,所以只截取Group0出來。
Group 0: (Blocks 1-8192) <==塊組0的塊起始/結束號碼
主 superblock at 1, Group descriptors at 2-2 <==超級塊在1號塊
保留的GDT塊位於 3-258
Block bitmap at 259 (+258), Inode bitmap at 260 (+259)
Inode表位於 261-513 (+260) <==inode表所在的塊
7665 free blocks, 2013 free inodes, 2 directories
……
我想現在對一個文件系統在磁碟里的結構已經明朗了。下面來認識inode表與數據域的關係。
數據域(data block)是用來存放文件內容數據的地方,inode表就是存放inode的地方。操作系統通過inode來找到指定的文件存放在哪個數據塊中,或存放在哪幾個數據塊中。一個數據塊最多只能存放一個文件,一個大的文件可以佔用多個數據塊。一個inode只能指向一個文件。inode中記錄文件的各種屬性數據加若干個指向文件真正內容所在數據塊的指針。用ls-li命令所看到內容,除了文件名,都是記錄在inode中的。我先將剛才那個分區掛載上再繼續說明。
# mount /dev/loop0 /mnt/ <==這樣就掛載上了
# cd /mnt/;touch foo1;ls -l
總用量 12
-rw-r--r-- 1 root root 0 4月 27 22:25 foo1
從上面的ls-l的結果中看到,inode中記錄了文件的各種許可權,屬主/屬組,創建時間,還有其它各種時間。(ls加上i選項能看到指向這個文件的inode所在的塊編號)。
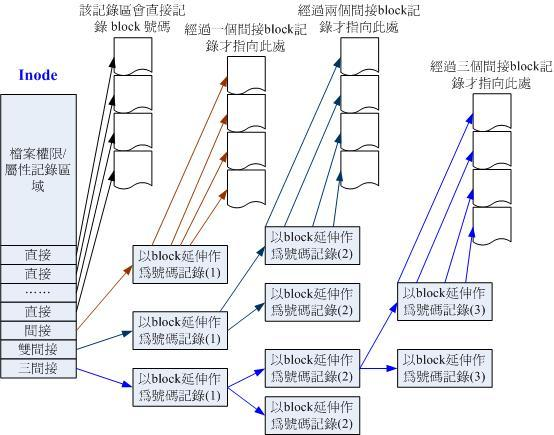
但是系統是怎麼通過inode找到數據塊的呢?每個inode的大小是128bytes,而inode記錄一個塊號碼要花掉4bytes。假設我一個 400MB大小的文件,每個數據塊為4k時, 那麼至少也要十萬筆塊號碼?記錄,區區128位元組,inode是怎麼記錄下的?下面給出一張inode的結構圖。
上圖最左邊為inode本身。裡邊有12個直接指向塊地址的指針。而間接指針也是指向塊地址,然後利用那個塊繼續指向別的塊。以1k大小的塊來計算這樣一個inode能指定多少個塊。如下:
12個直接: 12*1K=12K
間接: 256*1K=256K
每筆塊號碼記錄花去4bytes,因此1K的塊能記錄256筆記錄,因此一個間接可以記錄的檔案大小如上;
雙間接: 256*256*1K=2562K
第一層塊會指定256個第二層,每個第二層可以指定256個號碼,因此總額大小如上;再接下來同理:
三間接: 256*256*256*1K=2563K
總額:將直接、間接、雙間接、三間接加總,得到 12 + 256 + 256*256 + 256*256*256 (K) =16GB
如此,得出一個文件最大大小為16GB,當塊大小為1k的情況。我以為,本文之中,理解了這張圖,便理解了全文的一半。
當我們創建一個目錄時,ext3文件系統會分配一個inode與至少一個數據塊給該目錄文件。是的,目錄就是一個文件,Linux中,萬物皆文件。只不過假如目錄中存在文件,這個目錄的內容就是其下文件的文件名和與它對應的inode編號。這樣想讀取其中文件的內容時,實際是找到這個inode,然後找到實際的數據塊。如果你知道程序語言中變數的概念,並且了解一點指針的概念,目錄中的文件名實際上就是指向這個文件實際內容的inode的變數名。目錄名本身是一樣的道理。下面通過讀取目錄中的文件的過程分析這一過程。
# mkdir dir2;touch dir2/foo2
# ls -li / /mnt /mnt/dir2/
2 drwxr-xr-x 4 root root 1024 4月 27 23:41 mnt
10121 drwxr-xr-x 2 root root 1024 4月 27 23:41 dir2
10122 -rw-r--r-- 1 root root 0 4月 27 23:41 foo2
現在要讀取foo2的內容,這個讀取流程為:
系統設定編號為2的inode指向一個文件系統的根目錄所在的塊。通過2號inode,讀取到mnt所在塊的內容,裡邊記著dir2=10121,這個值就是dir2的inode編號;再通過這個inode讀取到dir2所在塊的內容,裡邊記著foo2=10122,從而通過這個指向讀取到foo2所在塊的內容。
事實上掛載的過程,實際就是2號inode的變數名等於那個目錄名,然後在它所在的數據塊中存放其下第一層各目錄的文件名=inode地址。前面已經說過,一個inode只指向一個文件。下面來看一個例子:
# ls -lid / /. /..
2 drwxr-xr-x 22 root root 4096 4月 15 12:01 /
2 drwxr-xr-x 22 root root 4096 4月 15 12:01 /. <==這個表示當前目錄
2 drwxr-xr-x 22 root root 4096 4月 15 12:01 /.. <==根目錄的
這三個文件都對應於編號為2的inode,指向的是同一個數據塊的內容,這說明這三是同一個文件。下面來區別一下硬鏈接與符號鏈接,來加強一下對inode 的認識。希望是更清楚,而不是更混沌,事實上,我隱約感覺到,我把問題說的更不易理解了。先建一個硬鏈接hlfoo1,再一個符號鏈接slfoo1,觀察 inode編號的變化。
# ln foo1 hlfoo1;ln -s foo1 slfoo1
12 -rw-r--r-- 2 root root 0 4月 27 22:25 foo1
12 -rw-r--r-- 2 root root 0 4月 27 22:25 hlfoo1
13 lrwxrwxrwx 1 root root 4 4月 28 00:22 slfoo1 -> foo1
可見,硬鏈接只是在某目錄文件(這個例子是當前目錄)的內容中添加了一筆文件名與相同inode編號的記錄。可以理解為兩個變數名代表用一個inode 了。正如hlfoo1=foo1。而符號鏈接文件系統新分配了一個inode,賦予變數名slyoo1,指向一個數據塊,存放著鏈接文件的文件名。觀察 slfoo1的文件大小,4bytes,正里存放著「foo1」。
文件系統的內容實在太廣,我不準備繼續講了。對於文件系統的學習,我覺得更重要的還是各種相關工具的學習,比如cfdisk、mkfs、fsck、mount/umount、等分區掛載的學習。
這篇文章,不能將這塊內容講得更明白(我擔心根本就沒講明白),又不忍刪之。實力所不能及,君海涵。
最後,實驗完了,卸盤刪除
/# umount /dev/loop0
/# losetup -d /dev/loop0
/# rmmod loop