良好的操作系統性能部分依賴於操作系統有效管理資源的能力.在過去,堆內存管理器是實際的規範,但是其性能會受到內存碎片和內存回收需求的影響.現 在,Linux? 內核使用了源自於 Solaris 的一種方法,但是這種方法在嵌入式系統中已經使用了很長時間了,它是將內存作為對象按照大小進行分配.本文將探索 slab 分配器背後所採用的思想,並介紹這種方法提供的介面和用法.
動態內存管理
內存管理的目標是提供一種方法,為實現各種目的而在各個用戶之間實現內存共享.內存管理方法應該實現以下兩個功能:
· 最小化管理內存所需的時間
· 最大化用於一般應用的可用內存(最小化管理開銷)
內存管理實際上是一種關於權衡的零和遊戲.您可以開發一種使用少量內存進行管理的演算法,但是要花費更多時間來管理可用內 存.也可以開發一個演算法來有效地管理內存,但卻要使用更多的內存.最終,特定應用程序的需求將促使對這種權衡作出選擇.
每個內存管理器都使用了一種基於堆的分配策略.在這種方法中,大塊內存(稱為 堆)用來為用戶定義的目的提 供內存.當用戶需要一塊內存時,就請求給自己分配一定大小的內存.堆管理器會查看可用內存的情況(使用特定演算法)並返回一塊內存.搜索過程中使用的一些算 法有 first-fit(在堆中搜索到的第一個滿足請求的內存塊 )和 best-fit(使用堆中滿足請求的最合適的內存塊).當用戶使用完內存后,就將內存返回給堆.
這種基於堆的分配策略的根本問題是碎片(fragmentation).當內存塊被分配后,它們會以不同的 順序在不同的時間返回.這樣會在堆中留下一些洞,需要花一些時間才能有效地管理空閑內存.這種演算法通常具有較高的內存使用效率(分配需要的內存),但是卻 需要花費更多時間來對堆進行管理.
另外一種方法稱為 buddy memory allocation,是一種更快的內存分配技術,它將內存 劃分為 2 的冪次方個分區,並使用 best-fit 方法來分配內存請求.當用戶釋放內存時,就會檢查 buddy 塊,查看其相鄰的內存塊是否也已經被釋放.如果是的話,將合併內存塊以最小化內存碎片.這個演算法的時間效率更高,但是由於使用 best-fit 方法的緣故,會產生內存浪費.
本文將著重介紹 Linux 內核的內存管理,尤其是 slab 分配提供的機制.
slab 緩存
Linux 所使用的 slab 分配器的基礎是 Jeff Bonwick 為 SunOS 操作系統首次引入的一種演算法.Jeff 的分配器是圍繞對象緩存進行的.在內核中,會為有限的對象集(例如文件描述符和其他常見結構)分配大量內存.Jeff 發現對內核中普通對象進行初始化所需的時間超過了對其進行分配和釋放所需的時間.因此他的結論是不應該將內存釋放回一個全局的內存池,而是將內存保持為針 對特定目而初始化的狀態.例如,如果內存被分配給了一個互斥鎖,那麼只需在為互斥鎖首次分配內存時執行一次互斥鎖初始化函數(mutex_init) 即可.後續的內存分配不需要執行這個初始化函數, 從上次釋放和調用析構之後,它已經處於所需的狀態中了.
從上次釋放和調用析構之後,它已經處於所需的狀態中了.
Linux slab 分配器使用了這種思想和其他一些思想來構建一個在空間和時間上都具有高效性的內存分配器.
圖 1 給出了 slab 結構的高層組織結構.在最高層是 cache_chain,這是一 個 slab 緩存的鏈接列表.這對於 best-fit 演算法非常有用,可以用來查找最適合所需要的分配大小的緩存(遍歷列表).cache_chain 的每個元素都是一個 kmem_cache 結構的引用(稱為一個 cache).它定義了一個要管理的給定大小的 對象池.
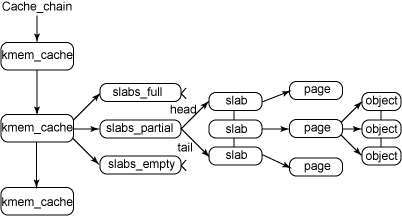
圖 1. slab 分配器的主要結構
每個緩存都包含了一個 slabs 列表,這是一段連續的內存塊(通常都是頁面).存在 3 種 slab:
slabs_full
完全分配的 slab
slabs_partial
部分分配的 slab
slabs_empty
空 slab,或者沒有對象被分配
注意 slabs_empty 列表中的 slab 是進行回收(reaping)的主要備選對象.正是通過此過程,slab 所使用的內存被返回給操作系統供其他用戶使用.
slab 列表中的每個 slab 都是一個連續的內存塊(一個或多個連續頁),它們被劃分成一個個對象.這些對象是從特定緩存中進行分配和釋放的基本元素.注意 slab 是 slab 分配器進行操作的最小分配單位,因此如果需要對 slab 進行擴展,這也就是所擴展的最小值.通常來說,每個 slab 被分配為多個對象.
由於對象是從 slab 中進行分配和釋放的,因此單個 slab 可以在 slab 列表之間進行移動.例如,當一個 slab 中的所有對象都被使用完時,就從 slabs_partial 列表中移動到 slabs_full 列表中.當一個 slab 完全被分配並且有對象被釋放后,就從 slabs_full 列表中移動到 slabs_partial 列表中.當所有對象都被釋放之後,就從 slabs_partial 列表移動到 slabs_empty 列表中.
slab 背後的動機
與傳統的內存管理模式相比, slab 緩存分配器提供了很多優點. ,內核通常依賴於對小對象的分配,它們會在系統生命周期內進行無數次分配.slab 緩存分配器通過對類似大小的對象進行緩存而提供這種功能,從而避免了常見的碎片問題.slab 分配器還支持通用對象的初始化,從而避免了為同一目而對一個對象重複進行初始化.
,內核通常依賴於對小對象的分配,它們會在系統生命周期內進行無數次分配.slab 緩存分配器通過對類似大小的對象進行緩存而提供這種功能,從而避免了常見的碎片問題.slab 分配器還支持通用對象的初始化,從而避免了為同一目而對一個對象重複進行初始化. ,slab 分配器還可以支持硬體緩存對齊和著色,這允許不同緩存中的對象佔用相同的緩存行,從而提高緩存的利用率並獲得更好的性能.
,slab 分配器還可以支持硬體緩存對齊和著色,這允許不同緩存中的對象佔用相同的緩存行,從而提高緩存的利用率並獲得更好的性能.
API 函數
現在來看一下能夠創建新 slab 緩存、向緩存中增加內存、銷毀緩存的應用程序介面(API)以及 slab 中對對象進行分配和釋放操作的函數.
第一個步驟是創建 slab 緩存結構,您可以將其靜態創建為:
struct struct kmem_cache *my_cachep;
slab 緩存的 Linux 源代碼
您可以在 ./linux/mm/slab.c 中找到 slab 緩存的源代碼. kmem_cache 結構也是在 ./linux/mm/slab.c 中定義的.本文著重討論 2.6.21 Linux 內核中的當前實現.
然後其他 slab 緩存函數將使用該引用進行創建、刪除、分配等操作.kmem_cache 結構包含了每個中央處理器單元(CPU)的數據、一組可調整的(可以通過 proc 文件系統訪問)參數、統計信息和管理 slab 緩存所必須的元素.
kmem_cache_create
內核函數 kmem_cache_create 用來創建一個新緩存.這通常是在內核初始化時執行的,或者在首次載入內核模塊時執行.其原型定義如下:
struct kmem_cache *
kmem_cache_create( const char *name, size_t size, size_t align,
unsigned long flags;
void (*ctor)(void*, struct kmem_cache *, unsigned long),
void (*dtor)(void*, struct kmem_cache *, unsigned long));
name 參數定義了緩存名稱,proc 文件系統(在 /proc/slabinfo 中)使用它標識這個緩存. size 參數指定了為這個緩存創建的對象的大小, align 參數定義了每個對象必需的對齊. flags 參數指定了為緩存啟用的選項.這些標誌如表 1 所示.
表 1. kmem_cache_create 的部分選項(在 flags 參數中指定)
| 選項(在 flags 參數中指定) | 說明 |
| SLAB_RED_ZONE | 在 對象頭、尾插入標誌,用來支持對緩衝區溢出的檢查. |
| SLAB_POISON | 使 用一種己知模式填充 slab,允許對緩存中的對象進行監視(對象屬對象所有,不過可以在外部進行修改). |
| SLAB_HWCACHE_ALIGN | 指定緩存對象必須與硬體緩存行對齊. |
ctor 和 dtor 參數定義了一個可選的對象構造器和析構器.構造器和析構器是用戶提供的回調函數.當從緩存中分配新對象時,可以通過構造器進行初始化.
在創建緩存之後, kmem_cache_create 函數會返回對它的引用.注意這個函數並沒有向緩存分配任何內存.相反,在試圖從緩存(最初為空)分配對象時,refill 操作將內存分配給它.當所有對象都被使用掉時,也可以通過相同的操作向緩存添加內存.
kmem_cache_destroy
內核函數 kmem_cache_destroy 用來銷毀緩存.這個調用是由內核模塊在被卸載時執行的.在調用這個函數時,緩存必須為空.
void kmem_cache_destroy( struct kmem_cache *cachep );
kmem_cache_alloc
要從一個命名的緩存中分配一個對象,可以使用 kmem_cache_alloc 函數.調用者提供了從中分配對象的緩存以及一組標誌:
void kmem_cache_alloc( struct kmem_cache *cachep, gfp_t flags );
這個函數從緩存中返回一個對象.注意如果緩存目前為空,那麼這個函數就會調用 cache_alloc_refill 向緩存中增加內存. kmem_cache_alloc 的 flags 選項與 kmalloc 的 flags 選項相同.表 2 給出了標誌選項的部分列表.
表 2. kmem_cache_alloc 和 kmalloc 內核函數的標誌選項
| 標誌 | 說明 |
| GFP_USER | 為 用戶分配內存(這個調用可能會睡眠). |
| GFP_KERNEL | 從 內核 RAM 中分配內存(這個調用可能會睡眠). |
| GFP_ATOMIC | 使 該調用強制處於非睡眠狀態(對中斷處理程序非常有用). |
| GFP_HIGHUSER | 從 高端內存中分配內存. |
對於 NUMA(Non-Uniform Memory Access)架構來說,對某個特定節點的分配函數是 kmem_cache_alloc_node.
kmem_cache_zalloc
內核函數 kmem_cache_zalloc 與 kmem_cache_alloc 類似,只不過它對對象執行 memset 操作,用來在將對象返回調用者之前對其進行清除操作.
kmem_cache_free
要將一個對象釋放回 slab,可以使用 kmem_cache_free.調用者提供了緩存引用和要釋放的對象.
void kmem_cache_free( struct kmem_cache *cachep, void *objp );
kmalloc和kfree
內核中最常用的內存管理函數是 kmalloc 和 kfree 函數.這兩個函數的原型如下:
void *kmalloc( size_t size, int flags );
void kfree( const void *objp );
注意在 kmalloc 中,惟一兩個參數是要分配的對象的大小和一組標誌(請參看 表 2 中的部分列表).但是 kmalloc 和 kfree 使用了類似於前面定義的函數的 slab 緩存.kmalloc 沒有為要從中分配對象的某個 slab 緩存命名,而是循環遍歷可用緩存來查找可以滿足大小限制的緩存.找到之後,就(使用 __kmem_cache_alloc)分配一個對象.要使用 kfree 釋放對象,從中分配對象的緩存可以通過調用 virt_to_cache 確定.這個函數會返回一個緩存引用,然後在 __cache_free 調用中使用該引用釋放對象.
通用對象分配
在 slab 源代碼中,提供了一個名為 kmem_find_general_cachep 的函數,可執行緩存搜索,即用來查找最適合所需對象大小的 slab 緩存.
其他函數
slab 緩存 API 還提供了其他一些非常有用的函數. kmem_cache_size 函數會返回這個緩存所管理的對象的大小.您也可以通過調用 kmem_cache_name 來檢索給定緩存的名稱(在創建緩存時定義).緩存可以通過釋放其中的空閑 slab 進行收縮.這可以通過調用 kmem_cache_shrink 實現.注意這個操作(稱為回收)是由內核定期自動執行的(通過 kswapd).
unsigned int kmem_cache_size( struct kmem_cache *cachep );
const char *kmem_cache_name( struct kmem_cache *cachep );
int kmem_cache_shrink( struct kmem_cache *cachep );
slab緩存的示例用法
下面的代碼片斷展示了創建新 slab 緩存、從緩存中分配和釋放對象然後銷毀緩存的過程.,必須要定義一個 kmem_cache 對象,然後對其進行初始化(請參看清單 1).這個特定的緩存包含 32 位元組的對象,並且是硬體緩存對齊的(由標誌參數 SLAB_HWCACHE_ALIGN 定義).
清單 1. 創建新 slab 緩存
static struct kmem_cache *my_cachep;
static void init_my_cache( void )
{
my_cachep = kmem_cache_create(
"my_cache", /* Name */
32, /* Object Size */
0, /* Alignment */
SLAB_HWCACHE_ALIGN, /* Flags */
NULL, NULL ); /* Constructor/Deconstructor */
return;
}
使用所分配的 slab 緩存,您現在可以從中分配一個對象了.清單 2 給出了一個從緩存中分配和釋放對象的例子.它還展示了兩個其他函數的用法.
清單 2. 分配和釋放對象
int slab_test( void )
{
void *object;
printk( "Cache name is %sn", kmem_cache_name( my_cachep ) );
printk( "Cache object size is %dn", kmem_cache_size( my_cachep ) );
object = kmem_cache_alloc( my_cachep, GFP_KERNEL );
if (object) {
kmem_cache_free( my_cachep, object );
}
return 0;
}
,清單 3 演示了 slab 緩存的銷毀.調用者必須確保在執行銷毀操作過程中,不要從緩存中分配對象.
清單 3. 銷毀 slab 緩存
static void remove_my_cache( void )
{
if (my_cachep) kmem_cache_destroy( my_cachep );
return;
}
slab 的proc 介面
proc 文件系統提供了一種簡單的方法來監視系統中所有活動的 slab 緩存.這個文件稱為 /proc/slabinfo,它除了提供一些可以從用戶空間訪問的可調整參數之外,還提供了有關所有 slab 緩存的詳細信息.當前版本的 slabinfo 提供了一個標題,這樣輸出結果就更具可讀性.對於系統中的每個 slab 緩存來說,這個文件提供了對象數量、活動對象數量以及對象大小的信息(除了每個 slab 的對象和頁面之外).另外還提供了一組可調整的參數和 slab 數據.
要調優特定的 slab 緩存,可以簡單地向 /proc/slabinfo 文件中以字元串的形式迴轉 slab 緩存名稱和 3 個可調整的參數.下面的例子展示了如何增加 limit 和 batchcount 的值,而保留 shared factor 不變(格式為 「cache name limit batchcount shared factor」):
# echo "my_cache 128 64 8" > /proc/slabinfo
limit 欄位表示每個 CPU 可以緩存的對象的最大數量. batchcount 欄位是當緩存為空時轉換到每個 CPU 緩存中全局緩存對象的最大數量. shared 參數說明了對稱多處理器(Symmetric MultiProcessing,SMP)系統的共享行為.
注意您必須具有超級用戶的特權才能在 proc 文件系統中為 slab 緩存調優參數.
SLOB 分配器
對於小型的嵌入式系統來說,存在一個 slab 模擬層,名為 SLOB.這個 slab 的替代品在小型嵌入式 Linux 系統中具有優勢,但是即使它保存了 512KB 內存,依然存在碎片和難於擴展的問題.在禁用 CONFIG_SLAB 時,內核會回到這個 SLOB 分配器中.更多信息請參看 參 考資料 一節.
結束語
slab 緩存分配器的源代碼實際上是 Linux 內核中可讀性較好的一部分.除了函數調用的間接性之外,源代碼也非常直觀,總的來說,具有很好的註釋.如果您希望了解更多有關 slab 緩存分配器的內容,建議您從源代碼開始,它是有關這種機制的最新文檔.
[火星人 ] Linux slab分配器剖析已經有772次圍觀
