這是使用開源工具 Ganglia 和 Nagios 手動監視數據中心 系列 的第二篇文章。在第 2 部分中,將學習如何安裝和配置 Nagios、常見的開源計算機系統、觀察託管和服務的網路監視應用程序軟體,並學習如何在出現問題時警告用戶。本文還演示如何結合 Nagios 和 Ganglia(接 Ganglia 和 Nagios,第 1 部分:用 Ganglia 監視企業集群),如何為 Nagios 標準集群、網格、雲添加兩個額外特性,以幫助監視網路交換機和資源管理器。
第 1 部分回顧
數據中心正在不斷增長,而管理職員卻在縮減,因此公司迫切需要監視計算資源的工具。本系列的第 1 部分討論了結合使用 Ganglia 和 Nagios 的好處,然後向您展示了如何使用自定義的監視腳本安裝和擴展 Ganglia。
回顧 Ganglia 和 Nagios,第 1 部分:用 Ganglia 監視企業集群 中的多個監視 定義(取決於運行的環境):
您可以找到代碼來監視希望監視的內容,也可以 從開源代碼中找到類似功能。使用開源監視工具最困難的地方在於,實現安裝后如何找出最適合所在環境的配置。開源(和商業)監視軟體有兩個主要問題如下:
Ganglia 是一個監視數據中心的工具,頻繁用於高性能計算環境中(但是對於其他環境,比如雲、渲染場、寄存中心,它的吸引力也是很大的)。它更重視收集標準然後隨時跟蹤,而 Nagios 主要關注警告機制。Ganglia 用來請求代理在每個主機上運行,以收集主機信息,但是通過 Ganglia 的欺騙機制,現在可以輕鬆獲取所有標準。Ganglia 沒有內置的通知機制,但是它可以在目標主機上支持可擴展的內置代理。
學習了第 1 部分之後,您可能已經安裝了 Ganglia,也能回答不同用戶組可能諮詢的監視問題。您也可能已經配置了基本的 Ganglia 設置,使用 Python 模塊擴展 IPMI(Intelligent Platform Management Interface,智能平台管理界面)的功能,並使用 Ganglia 主機欺騙機制監視 IPMI。
現在,讓我們了解一下 Nagios。
  |
Nagios 簡介
該部分演示如何安裝 Nagios 並綁定 Ganglia。我們將向 Nagios 添加兩個特性,幫助您監視標準集群、網格、雲(以及任何擴展計算的功能)。這兩個特性的作用是:
在本例中,我們將監視 TORQUE。完成之後,您將擁有一個控制監視整個數據中心繫統的框架。
Nagios 與 Ganglia 一樣,常用於 HPC 和其他環境,但是 Nagios 更加關注警告機制,Ganglia 則更加關注收集和跟蹤指標。Nagios 以前只是從目標主機收集信息,但最近開發了可以在主機上運行代理的插件。Nagios 內置了一個通知系統。
現在我們安裝 Nagios 並安裝基本的 HPC Linux® 監視系統集群以滿足不同的監視需求:
|
安裝 Nagios
在機器上安裝 Nagios 的方法可以從 Internet 查詢。因為我經常需要在不同的環境中安裝,所以為此編寫了一個腳本。
首先需要 下載兩個包:
插件包括:
獲取源代碼並放在目錄中。為了演示,我在 /tmp 中放置了三個文件:
清單 1 展示了 naginstall.sh 安裝腳本:
#!/bin/ksh NAGIOSSRC=nagios-3.0.6 NAGIOSPLUGINSRC=nagios-plugins-1.4.13 NAGIOSCONTACTSCFG=/usr/local/nagios/etc/objects/contacts.cfg NAGIOSPASSWD=/usr/local/nagios/etc/htpasswd.users PASSWD=cluster OS=foo function buildNagiosPlug { if [ -e $NAGIOSPLUGINSRC.tar.gz ] then echo "found $NAGIOSPLUGINSRC.tar.gz building and installing Nagios" else echo "could not find $NAGIOSPLUGINSRC.tar.gz in current directory." echo "Please run $0 in the same directory as the source files." exit 1 fi echo "Extracting Nagios Plugins..." tar zxf $NAGIOSPLUGINSRC.tar.gz cd $NAGIOSPLUGINSRC echo "Configuring Nagios Plugins..." if ./configure --with-nagios-user=nagios --with-nagios-group=nagios -prefix=/usr/local/nagios > config.LOG.$ 2>&1 then echo "Making Nagios Plugins..." if make -j8 > make.LOG.$ 2>&1 then make install > make.LOG.$ 2>&1 else echo "Make failed of Nagios plugins. See $NAGIOSPLUGINSRC/make.LOG.$" exit 1 fi else echo "configure of Nagios plugins failed. See config.LOG.$" exit 1 fi echo "Successfully built and installed Nagios Plugins!" cd .. } function buildNagios { if [ -e $NAGIOSSRC.tar.gz ] then echo "found $NAGIOSSRC.tar.gz building and installing Nagios" else echo "could not find $NAGIOSSRC.tar.gz in current directory." echo "Please run $0 in the same directory as the source files." exit 1 fi echo "Extracting Nagios..." tar zxf $NAGIOSSRC.tar.gz cd $NAGIOSSRC echo "Configuring Nagios..." if ./configure --with-command-group=nagcmd > config.LOG.$ 2>&1 then echo "Making Nagios..." if make all -j8 > make.LOG.$ 2>&1 then make install > make.LOG.$ 2>&1 make install-init > make.LOG.$ 2>&1 make install-config > make.LOG.$ 2>&1 make install-commandmode > make.LOG.$ 2>&1 make install-webconf > make.LOG.$ 2>&1 else echo "make all failed. See log:" echo "$NAGIOSSRC/make.LOG.$" exit 1 fi else echo "configure of Nagios failed. Please read $NAGIOSSRC/config.LOG.$ for details." exit 1 fi echo "Done Making Nagios!" cd .. } function configNagios { echo "We'll now configure Nagios." LOOP=1 while [[ $LOOP -eq 1 ]] do echo "You'll need to put in a user name. This should be the person" echo "who will be receiving alerts. This person should have an account" echo "on this server. " print "Type in the userid of the person who will receive alerts (e.g. bob)> \c" read NAME print "What is ${NAME}'s email?> \c" read EMAIL echo echo echo "Nagios alerts will be sent to $NAME at $EMAIL" print "Is this correct? [y/N] \c" read YN if [[ "$YN" = "y" ]] then LOOP=0 fi done if [ -r $NAGIOSCONTACTSCFG ] then perl -pi -e "s/nagiosadmin/$NAME/g" $NAGIOSCONTACTSCFG EMAIL=$(echo $EMAIL | sed s/\@/\\\\@/g) perl -pi -e "s/nagios\@localhost/$EMAIL/g" $NAGIOSCONTACTSCFG else echo "$NAGIOSCONTACTSCFG does not exist" exit 1 fi echo "setting ${NAME}'s password to be 'cluster' in Nagios" echo " you can change this later by running: " echo " htpasswd -c $NAGIOSPASSWD $Name)'" htpasswd -bc $NAGIOSPASSWD $NAME cluster if [ "$OS" = "rh" ] then service httpd restart fi } function preNagios { if [ "$OS" = "rh" ] then echo "making sure prereqs are installed" yum -y install httpd gcc glibc glibc-common gd gd-devel perl-TimeDate /usr/sbin/useradd -m nagios echo $PASSWD | passwd --stdin nagios /usr/sbin/groupadd nagcmd /usr/sbin/usermod -a -G nagcmd nagios /usr/sbin/usermod -a -G nagcmd apache fi } function postNagios { if [ "$OS" = "rh" ] then chkconfig --add nagios chkconfig nagios on # touch this file so that if it doesn't exist we won't get errors touch /var/www/html/index.html service nagios start fi echo "You may now be able to access Nagios at the URL below:" echo "http://localhost/nagios" } if [ -e /etc/redhat-release ] then echo "installing monitoring on Red Hat system" OS=rh fi # make sure you're root: ID=$(id -u) if [ "$ID" != "0" ] then echo "Must run this as root!" exit fi preNagios buildNagios buildNagiosPlug configNagios postNagios |
運行腳本 ./naginstall.sh
該代碼在 Red Hat 系統上能正常運行,如果您安裝了本系列 Ganglia 和 Nagios,第 1 部分:用 Ganglia 監視企業集群 中提到的所有依賴關係,那麼應該也能正常運行。運行 naginstall.sh 時,提示 Nagios 應該發送警告的用戶。稍後可以添加其他用戶。大部分組織都有一個郵件別名以組的形式發送郵件。
如果安裝時出現問題,可以查看 Nagios 網頁(鏈接見 參考資料)並將其添加到郵件列表。以我的經驗看來,像 Nagios 和 Ganglia 這樣成功的大部分包都很容易安裝。
|
配置 Nagios
假設腳本運行正常並且已經安裝了所有內容。那麼在腳本成功退出時,您應該能夠打開 Web 瀏覽器並看到 localhost 已經被監視了(如圖 1 所示):
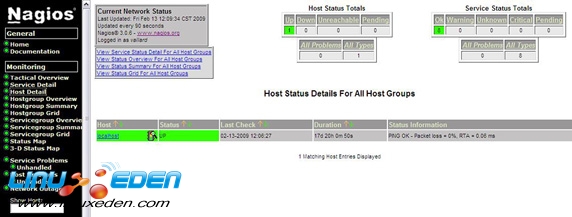
通過單擊 Service Detail,您可以看到我們監視本地機器上的哪些服務(比如 Ping、HTTP、載入、用戶等等),這是默認配置的。
讓我們看看名為 Root Partition 的服務。該服務在根分區滿時發出警告。通過查看安裝時生成的配置文件,您可以完全理解該檢查的工作方式。
主配置文件
如果使用 naginstall.sh 腳本,則主配置文件是 /usr/local/nagios/etc/nagios.cfg。該腳本展示幾個帶有其他定義的 cfg_files。其中的行如下:
cfg_file=/usr/local/nagios/etc/objects/localhost.cfg
如果查看該文件,您將看到所有用於 Web 視圖中出現的 localhost 的服務。這就是配置默認服務的地方。根分區定義見第 77 行。
根分區檢查方式的體系結構見圖 2。
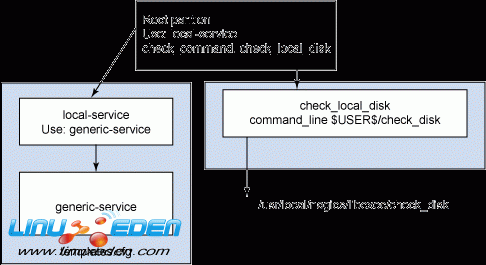
首先要注意 Nagios 對象的繼承模式。根分區 的定義使用本地服務定義,本地服務定義則使用通用服務定義。這定義了調用服務的方式、頻率以及其他可調試參數等等。
接下來重要的定義部分是使用的檢查命令。首先它使用名為 check_local_disk 的命令定義。傳遞的參數是 !20%!10%!/。表示當 check_local_disk 命令定義報告 20% 時,它將發出警告。當它到達 10% 時,您將得到一個嚴重錯誤。/ 表示它檢查 "/" 分區。check_local_disk 隱式調用 check_disk 命令,該命令位於 /usr/local/nagios/libexec 目錄中。
這是設置這些配置的基本思路。您可以按照該思路創建自己的服務來監視所需的參數。有關更深入的內容,請閱讀文檔並嘗試自己設置一些參數。
註冊以收到警告
所有配置完成後,註冊以收到警告。我們開始時已經完成了該操作,但是如果希望更改或添加用戶,則可以修改 /usr/local/nagios/etc/objects/contacts.cfg 文件。將聯繫人名稱改為您的名字,將電子郵件改為您的電子郵件地址。大部分基本的 Linux 伺服器應該已經設置好,可以處理郵件了。
現在配置其他節點。
在 grid/cloud/cluster 中配置其他節點
我在 Dallas 數據中心有一組節點。我將創建一個目錄放置所有配置文件:
mkdir -p /usr/local/nagios/etc/dallas
我需要通知 Nagios 我的配置文件將放在哪裡。為此我修改 nagios.cfg 文件,添加以下行:
cfg_dir=/usr/local/nagios/etc/dallas
我將在此創建一組文件(很容易讓人糊塗)。圖 3 顯示了這些條目以及它們所屬的文件,並展示了對象之間的關係。
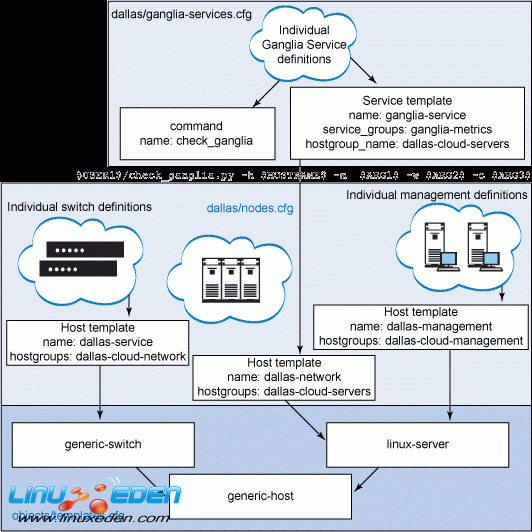
根據該圖繼續進行其他設置和安裝。
在 /usr/local/nagios/etc/dallas/nodes.cfg 文件中,我定義所有節點和節點組。我需要監視三種機器:
我創建三個相應的組,如下所示:
define hostgroup { hostgroup_name dallas-cloud-servers alias Dallas Cloud Servers } define hostgroup hostgroup_name dallas-cloud-network alias Dallas Cloud Network Infrastructure } define hostgroup hostgroup_name dallas-cloud-management alias Dallas Cloud Management Devides } |
接下來我創建三個模板文件,三個節點組的節點共享通用特徵:
define host { name dallas-management use linux-server hostgroups dallas-cloud-management # TEMPLATE! register 0 } define host { name dallas-server use linux-server hostgroups dallas-cloud-servers # TEMPLATE! register 0 } define host { name dallas-network use generic-switch hostgroups dallas-cloud-network # TEMPLATE! register 0 } |
現在我的每個節點定義為 dallas-management、dallas-server 或 dallas-network。各自的示例如下:
define host { use dallas-server host_name x336001 address 172.10.11.1 } define host { use dallas-network host_name smc001 address 172.10.0.254 } define host { use dallas-management host_name x346002-rsa address 172.10.11.12 } |
我生成了一個遍歷節點列表的腳本,並使用我的 Dallas 實驗室中的節點完全填充這個文件。當我重啟 Nagios 時,將檢查這些節點是否可以到達。但是我還有其他一些服務!
您應該首先重啟 Nagios 保證設置完成。如果已經完成,則應該在 HostGroup Overview 視圖下看到一些組。如果有錯誤,則運行:
/usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfg
這將驗證文件並幫助您發現錯誤。
現在可以添加一些基本的服務了。根據 localhost 中的模板,較容易完成的是查看 dallas-cloud-servers 組上的 SSH。讓我們啟動另一個文件:/usr/local/nagios/etc/dallas/host-services.cfg。最簡單的是將配置從希望監視的 localhost 中複製出來。我就是這樣做的,並添加了一個依賴關係:
define service{ use generic-service hostgroup_name dallas-cloud-servers service_description SSH check_command check_ssh } define service{ use generic-service hostgroup_name dallas-cloud-servers service_description PING check_command check_ping!100.0,20%!500.0,60% } define servicedependency{ hostgroup_name dallas-cloud-servers service_description PING dependent_hostgroup_name dallas-cloud-servers dependent_service_description SSH } |
如果 PING 無法正常工作,我不會考慮測試 SSH。現在開始可以添加各種內容了,但我們再看看其他東西。重啟 Nagios 並測試菜單,以確保看到 ping 和 ssh 檢查了節點:
service nagios reload
如果一切正常,我們將開始進入有趣的部分 —— 集成 Ganglia。
|
集成 Nagios 報告 Ganglia 指標
Nagios Exchange 是另一個獲取 Nagios 插件的好地方。但是對於我們的 Ganglia 插件,只要從 Ganglia 和 Nagios,第 1 部分:用 Ganglia 監視企業集群 中下載的源代碼中查找。假設您將源代碼解壓到 /tmp 目錄中,剩下的只需要複製 contrib 目錄中的 check_ganglia.py 腳本即可:
cp /tmp/ganglia-3.1.1/contrib/check_ganglia.py \ /usr/local/nagios/libexec/ |
check_ganglia 是一個很棒的 Python 腳本,可以運行於 gmetad 運行的伺服器上(在我的示例中是 Nagios 運行的管理伺服器)。讓我們在埠 8649 上查詢 localhost。使用這種方法,您可以通過遠程命令擴展網路通訊:可以使用 Ganglia 的擴展技術實現!
如果運行 telnet localhost 8649,您將看到從節點收集的數據中生成大量輸出(假設按照第 1 部分安裝了 Ganglia 並能正常運行)。讓我們監視一些 Ganglia 提供的內容。
進入 /var/lib/ganglia/rrds 目錄,您可以看到每個主機的度量指標。生成了易於查看的圖形,您可以一直分析指標。我們將度量 load_one 和 disk_free,由於在第 1 部分中我們啟用了 IPMI 溫度度量,我們將同樣添加該度量。
創建 /usr/local/nagios/etc/dallas/ganglia-services.cfg 文件並添加服務:
define servicegroup { servicegroup_name ganglia-metrics alias Ganglia Metrics } define command { command_name check_ganglia command_line $USER1$/check_ganglia.py -h $HOSTNAME$ -m $ARG1$ -w $ARG2$ -c $ARG3$ } define service { use generic-service name ganglia-service hostgroup_name dallas-cloud-servers service_groups ganglia-metrics notifications_enabled 0 } define service { use ganglia-service service_description load_one check_command check_ganglia!load_one!4!5 } define service { use ganglia-service service_description ambient_temp check_command check_ganglia!AmbientTemp!20!30 } define service { use ganglia-service service_description disk_free check_command check_ganglia!disk_free!10!5 } |
重啟 Nagios 時,現在可以根據 Ganglia 指標發出警告!
提醒:check_ganglia.py 命令僅在閾值過高時發出警告。如果希望在閾值過低時發出警告(在 disk_free 中是這樣),則需要修改代碼。我更改了文件的最後部分,如下所示:
if critical > warning: if value >= critical: print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value) sys.exit(2) elif value >= warning: print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value) sys.exit(1) else: print "CHECKGANGLIA OK: %s is %.2f" % (metric, value) sys.exit(0) else: if critical >= value: print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value) sys.exit(2) elif warning >= value: print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value) sys.exit(1) else: print "CHECKGANGLIA OK: %s is %.2f" % (metric, value) sys.exit(0) |
現在重新載入 Nagios:
service nagios restart
如果一切正常,您應該看到 Ganglia 數據現在已經在 Nagios 的監視之下!
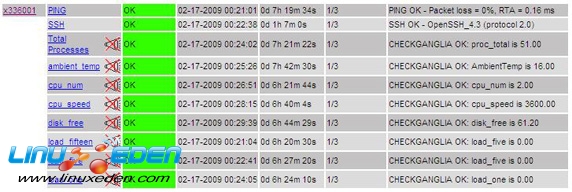
結合使用 Ganglia 和 Nagios,您可以監視任何內容。您可以控制整個雲!
|
擴展 Nagios:監視網路交換機
隨著雲和虛擬化的流程,原來的 “網路管理員” 和 “系統管理員” 之間的界線更加模糊起來。忽視配置網路交換機和理解網路技術的系統管理員將面臨過時的風險。
不用再擔心完整性,我將展示如何擴展 Nagios 來監視網路交換機。使用 Nagios(而不是網路交換機供應商的解決方案)監視網路交換機的優點很簡單 —— 使用 Nagios 您可以監視任何 供應商的交換機。看到 ping 成功后,我們將探討交換機上的 SNMP。
有些交換機默認啟用 SNMP。您可以根據供應商的說明設置。要在 Cisco Switch 上設置 SNMP,請參考以下示例,我的交換機的主機名為 c2960g:
telnet c2960g c2960g>enable c2960g#configure terminal c2960g(config)#snmp-server host 192.168.15.1 traps SNMPv1 c2960g(config)#snmp-server community public c2960g(config)#exit c2960g#copy running-config startup-config |
現在看看能夠監視的內容,運行 snmpwalk 並將其導出到文件:
snmpwalk -v 1 -c public c2960g
如果一切正常,您將看到許多內容傳遞迴來。然後可以捕獲輸出並查看各種要監視的位置。
我還有一個交換機示例。當我運行 snmpwalk 命令時,我看到埠以及做標記的方式。我對以下信息很感興趣:
為了監視這些內容我創建了一個新文件,/usr/local/nagios/etc/dallas/switch-services.cfg。我將網路主機映射到交換機,因此我對所有事情了如指掌。建議您也這樣做。如果想體驗真正的雲計算,就應該了解所有資源的狀態。
我將使用節點 x336001 作為示例。我知道它位於埠 5。我的文件如下所示:
define servicegroup { servicegroup_name switch-snmp alias Switch SNMP Services } define service { use generic-service name switch-service host_name smc001 service_groups switch-snmp } define service { use switch-service service_description Port5-MTU-x336001 check_command check_snmp!-o IF-MIB::ifMtu.5 } define service { use switch-service service_description Port5-Speed-x336001 check_command check_snmp!-o IF-MIB::ifSpeed.5 } define service { use switch-service service_description Port5-Status-x336001 check_command check_snmp!-o IF-MIB::ifOperStatus.5 } |
完成後,重啟 Nagios,您會發現現在我可以查看交換機了:

這只是如何監視交換機的一個示例。注意,我沒有設置警告,也沒有指出關鍵動作。您可能還注意到了,在 libexec 目錄中還有一些選項可以完成類似的功能。check_ifoperstatus 以及其他內容也需要技巧。使用 Nagios 時,可以使用多種方式完成一個任務。
|
擴展 Nagios:報告監視 TORQUE 的作業
可以根據 TORQUE 編寫許多腳本來確定該隊列系統的運行方式。在該擴展中,假設您已經安裝了 TORQUE。TORQUE 是一個可以與 Moab 和 Maui 結合使用的資源管理器。可以參考 Colin Morey 編寫的 開源 Nagios 插件。
下載並將其放在 /usr/local/nagios/libexec 目錄,確定它可以執行。我必須稍微修改代碼,將安裝 Nagios 的目錄從 use lib "/usr/nagios/libexec"; 更改為 use lib "/usr/local/nagios/libexec";。我還必須將 my $qstat = '/usr/bin/qstat' ; 更改為 qstat 命令。我的命令如下所示:my $qstat = '/opt/torque/x86_64/bin/qstat' ;。
驗證它能運行(我使用的隊列名為 dque):
[root@redhouse libexec]# ./check_pbs.pl -Q dque -tw 20 -tm 50 check_pbs.pl Critical: dque on localhost checked, Total number of jobs higher than 50. Total jobs:518, Jobs Queued:518, Jobs Waiting:0, Jobs Halted:0 |exectime=9340us |
您可以使用 -h 選項顯示更多要監視的內容。現在將它放置到配置文件 /usr/local/nagios/etc/dallas/torque.cfg:
define service { use generic-service host_name localhost service_description TORQUE Queues check_command check_pbs!20!50 } define command { command_name check_pbs command_line $USER1$/check_pbs.pl -Q dque -tw $ARG1$ -tm $ARG2$ } |
重啟 Nagios 之後,將在 localhost 下顯示該服務。

在我的例子中,我收到了一個嚴重警告,因為我的隊列中有 518 個作業!
顯然,跟蹤 TORQUE 和腳本有很多方式。您可以使用 pbsnodes 通知節點狀態。人們應該更關心節點的運行位置以及運行的作業。這個小示例將展示各種可能性,以及如何在很短的時間內完成監視解決方案。
|
結束語
閱讀了該系列之後,系統管理員應該能夠輕鬆運行 Ganglia 和 Nagios,以前所未有的方式監視其數據中心。這兩個包的範圍非常廣泛。我們在這裡接觸的只是與集群、網格和雲基礎結構相關的內容。
設置該監視解決方案的大部分時間都用於配置要監視的服務。許多現有的替代解決方案都是平台而不是成品。換句話說,它們提供框架來支持插件,但很少有預先建好的插件。大部分插件的工作由管理員和用戶完成,這些工作往往非常繁瑣。實際上,這就是大部分數據中心監視的內容。
Ganglia 和 Nagios 不僅僅是一個插件平台。(責任編輯:A6)
[火星人 ] Ganglia 和 Nagios,第 2 部分: 使用 Nagios 監視企業集群已經有1068次圍觀
