本文描述使用 Linux-HA 為複合應用程序實現高可用性。向複合應用程序交付高可用性具有很大的挑戰性。由於複合應用程序由一些不同類型的應用程序組成,每個應用程序都具有不同的可用性需求,所以配置相當複雜。在本文中,作者描述如何為複合應用程序 Tivoli® Maximo® 設計和實現一種高可用性原型。其中的配置腳本展示了如何使用系統化和優先化的故障轉移計劃,向由相關應用程序組成的異構集群提供高可用性。
在 2008 年,我們為一家大型在線企業開發了針對我們的 CMDB 實現(配置管理資料庫)Tivoli Maximo and Tivoli Application Dependency Discovery Manager 的高可用性解決方案。這家企業現在採用了 Maximo 的一種成熟的 CCMDB 實現(現在稱為 Tivoli Service Request Manager and Tivoli Asset Manager for IT),其中包含一個單一的企業級 Maximo(CCMDB 版本)。我們的目標在於使用多個域 CMDB 應用程序從不同的企業站點收集信息,並將這些信息聚合到一個企業 CMDB 實例中。對這些企業 CMDB 數據進行過濾並累積到 CCMDB 實例 Maximo 中。
Maximo 既存儲預設策略所描述的企業 WISB 的理想 CMDB 狀態(“應該處於的狀態”),還 存儲 CI 信息所表示的 WIRI 的實際狀態(實際處於的狀態),CI 信息收集自企業中部署的成千上萬個伺服器和應用程序。
一般而言,HA 層次結構中的不同功能節點要求不同的 HA 設計。例如,網關伺服器、普通 Windows® 計算機要求 MSCS。域 CMDB 應用程序要求 HA,但是使用冷備份就足夠了。而 Maximo 需要 24/7 可用性,並且 Maximo 和企業 CMDB 連接到自己的專用資料庫 — 這些資料庫通常是集群的一部分。但是在本文的原型中,我們主要討論應用程序的 HA 可用性,因此我們僅針對應用程序可用性進行設計。圖 1 給出了我們的設計。
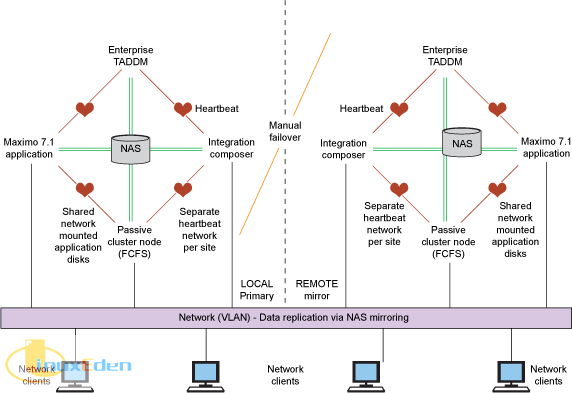
在本文中,我們描述一種管理高可用性、異構、包含多個應用程序的節點集群的方法。在高可用性集群中,每個應用程序都具有不同的可用性配置文件,這使我們的解決方案實際上比面向單一應用程序(比如資料庫)的簡單高可用性解決方案更加複雜。
我們的解決方案將採用一種演算法(協議)來適應高可用性集群中應用程序(或節點)的第一次和 第二次故障。這個協議為集群中的每個應用程序節點提供了精確的故障轉移順序。 它考慮了這樣的情形:性能不能降低,而且由於運行時衝突,不能在同一計算機上運行多個應用程序。
設計和實現特性包括:
HA 架構通常用於單一軟體類型,比如資料庫或 Web 伺服器。在我們的示例中,我們將展示如何實現 CCMDB 等應用程序的高可用性,該實現包含 3 個獨立的軟體組件:
安裝 HA
Linux-HA 安裝是一個簡單、直觀的過程(參見 參考資料,獲取軟體)。確保系統擁有正確的補丁級別,以滿足心跳(heartbeat)軟體的前提條件。我們用於演示的 Linux-HA 的版本為 2.1.4。
當安裝完成時,重啟計算機。必須執行這一步。為組成集群的所有 4 台計算機執行清單 1 中的步驟。
[root@hacluster2 tmp]# rpm -ivh perl-TimeDate-1.16-3_2.0.el5.noarch.rpm warning: perl-TimeDate-1.16-3_2.0.el5.noarch.rpm: Header V3 DSA signature: NOKEY, key ID 66534c2b Preparing ... ########################################### [100%] 1:perl-TimeDate ########################################### [100%] [root@hacluster2 tmp]# rpm -ivh heartbeat-pils-2.1.4-2.1.i386.rpm warning: heartbeat-pils-2.1.4-2.1.i386.rpm: Header V3 DSA signature: NOKEY, key ID 1d326aeb Preparing ... ########################################### [100%] 1:heartbeat-pils ########################################### [100%] [root@hacluster2 tmp]# rpm -ivh heartbeat-stonith-2.1.4-2.1.i386.rpm warning: heartbeat-stonith-2.1.4-2.1.i386.rpm: Header V3 DSA signature: NOKEY, key ID 1d326aeb Preparing ... ########################################### [100%] 1:heartbeat-stonith ########################################### [100%] [root@hacluster2 tmp]# rpm -ivh heartbeat-2.1.4-2.1.i386.rpm warning: heartbeat-2.1.4-2.1.i386.rpm: Header V3 DSA signature: NOKEY, key ID 1d326aeb Preparing ... ########################################### [100%] 1:heartbeat ########################################### [100%] [root@hacluster2 tmp]# |
  |
配置 HA
下一步是創建 ha.cf 文件。 創建以下文件:/etc/ha.d/ha.cf。ha.cf 文件存儲關於此設置涉及到哪些節點的信息。
在分配為 DC(designated coordinator)的機器上創建 ha.cf。創建此文件和 authkeys 文件之後,使用 FTP 或簡單 SCP 將它們複製到其他機器。因為 4 個節點(3 個應用程序和一個備用節點)都位於此集群中,我們的 ha.cf 文件類似於清單 2:
node hacluster1.svl.ibm.com hacluster2.svl.ibm.com hacluster3.svl.ibm.com hacluster4.svl.ibm.com bcast eth0 crm on |
在清單 2 中:
在清單 2 中,我們鍵入屬於此集群的機器的主機名。接下來,我們需要向 /etc/ha.d/authkeys 添加一個驗證密鑰。清單 3 給出了我們使用的示例:
# # Authentication file. Must be mode 600 # # # Must have exactly one auth directive at the front. # auth sne authentication using this method-id # # Then, list the method and key that go with that method-id # # Available methods: crc sha1, md5. Crc doesn't need/want a key. # # You normally only have one authentication method-id listed in this file # # Put more than one to make a smooth transition when changing wuth # methods and/or keys. # # # sha1 is believed to be the "best", md5 next best. # # crc adds no security, except from packet corruption. # Use only on physically secure networks. # auth 1 1 sha1 haclusteringisfun |
注意:這個文件的許可權必須為 0600。當這些文件創建之後,通過發出命令 /etc/init.d/heartbeat start 啟動 heartbeat。
在集群中的所有機器上運行清單 4 中所示的命令:
[root@hacluster1 heartbeat]# /etc/init.d/heartbeat start Starting High-Availability services: [ OK ] [root@hacluster1 heartbeat]# |
如果看到這條消息,則意味著您的 Linux-HA 安裝成功完成。現在,是時候測試複合應用程序的高可用性了。
添加一個 quorum 伺服器
在一個 2 節點集群中,當一個節點發生故障或網路連接中斷,每個節點都會充當主要節點並開始與外界交互。這是一種不利的競態條件。我們需要一個外部仲裁程序來要求其中一個節點暫時停止活動。
如果其中一個機器崩潰,仲裁程序將讓該機器暫時停止活動。這個仲裁程序稱為 quorum 伺服器,它可以是集群中的每個節點都可以到達的任何機器。將這個仲裁程序命名為 quorum 伺服器是因為它運行一個 quorum 監控程序。修改 ha.cf,將下面這行代碼添加到每個 ha.cf 文件:
cluster ourcmdb quorum_server hacluster4.svl.ibm.com |
quorum 伺服器機器不一定要運行 heartbeat,但是我們建議安裝 heartbeat,以便能夠訪問安裝 heartbeat 時創建的所有二進位文件和目錄路徑(比如 /etc/ha.d)。在 quorum 伺服器機器上,編輯文件 /etc/ha.d/quorumd.conf 並添加以下代碼:
cluster ourcmdb version 2_1_4 interval 1000 timeout 5000 takeover 3000 giveup 2000 |
然後,使用 quorumd 啟動 quorum 監控程序。確保它在計算機每次重啟時都會啟動。要自動啟動 quoromd,將其添加到 inetd 中。
Linux-HA 使用一個名為 cib.xml 的配置文件,在集群中的所有節點上啟動 heartbeat 時會自動創建該文件。這個 cib.xml 文件存儲應用程序配置(指定哪個應用程序擁有更高的優先順序,包括針對高可用性的規則)。您可以使用 GUI 工具(/usr/bin/hb_gui)修改 cib.xml,這是推薦方法,也可以手動修改。
Cib.xml 包含以下信息:
因為 cib.xml 受到 heartbeat 進程的控制,所以應避免在集群運行時修改此文件。
注意:cib.xml 上的許可權必須為 0600,並且必須歸 haclient:hacluster 所有。
Linux-HA 附帶了一組基於開放集群框架(Open Cluster Framework,OCF)的資源代理,該框架是用於實現高可用性的標準。在我們的場景中,因為所有應用程序都是定製的,我們必須為複合應用程序中包含的各個軟體組件構建 OCF 資源代理。
配置 heartbeat
清單 7 給出了我們使用的 heartbeat 版本中的資源配置。配置文件位於 /var/lib/heartbeat/crm/cib.xml。基本而言,此文件指定集群的資源以及應該在何處執行這些資源。
我們為此場景開發了一個 cib.xml 文件,參見 參考資料 獲取鏈接。我們為其添加了註釋,以使該進程更容易執行。
<cib generated="true" admin_epoch="0" have_quorum="true" ignore_dtd="false" num_peers="2" ccm_transition="2" cib_feature_revision="2.0" crm_feature_set="2.0" epoch="3" dc_uuid=" ad893965-d27d-4908-a2ea-868f1661f644" num_updates="3" cib-last-written="Fri Nov 14 10:14:40 2008"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <attributes/> </cluster_property_set> </crm_config> <nodes> /* Names of the nodes in the cluster */ <node id="ad893965-d27d-4908-a2ea-868f1661f644" uname="hacluster1.svl.ibm.com" type="normal"/> /* Maximo node */ <node id="5994eb92-0a13-4fc7-ab41-76098672fdbb" uname="hacluster3.svl.ibm.com" type="normal"/> /* ITIC node */ <node id="c14b9082-5b1a-481c-930a-561e926df7c3" uname="hacluster4.svl.ibm.com" type="normal"/> /* eCMDB node */ <node id="827b7884-06db-4d8d-994d-7e743b9bb969" uname="hacluster2.svl.ibm.com" type="normal"/> /* Spare node */ </nodes> <resources> <group id="maximo_group"> /* Assign base parameters for each application - Maximo */ <primitive class="lsb" id="maximo_id" type="maximo"> <operations> <op id="1" name="monitor" interval="10s"/> <op id="2" name="start" start_delay="10s"/> </operations> <meta_attributes id="063383a7-2c60-4cf0-b3b0-a3670328c3b8"> <attributes> /* Priority are set as weighting factors. This determines which application will be placed on the spare node in the event of a second failure. Here, Maximo > eCMDB > ITIC. Note that the first failure pushes the downed application onto the spare. A subsequent failure determines whether the initially downed application or the newly downed application takes precedence. */ <nvpair name="priority" value="3" id="f0c58dd3-43bb-4a1e-86cc-8993e58ba399"/> </attributes> </meta_attributes> </primitive> </group> <group id="iticd_group"> /* Assign base parameters for each application - ITIC */ <primitive class="lsb" id="itic_id" type="iticd"> <operations> <op id="3" name="monitor" interval="10s"/> <op id="4" name="start" start_delay="10s"/> </operations> <meta_attributes id="cb35cbb3-3241-4bf6-9ab7-f06d6f5baf89"> <attributes> <nvpair name="priority" value="2" id="7f7a35eb-aff8-4f7d-8e4d-ec6a0414d6da"/> </attributes> </meta_attributes> </primitive> </group> <group id="taddm_group"> /* Assign base parameters for each application - eCMDB */ <primitive class="lsb" id="taddm_id" type="taddm"> <operations> <op id="5" name="monitor" interval="10s"/> <op id="6" name="start" start_delay="10s"/> </operations> <meta_attributes id="e7baab9a-1460-423f-aabd-f68137d00d42"> <attributes> <nvpair name="priority" value="1" id="0448d632-f8e7-4347-90bd-de8222b77bda"/> </attributes> </meta_attributes> </primitive> </group> </resources> <constraints> <rsc_colocation id="not_same_1" to="maximo_group" from="iticd_group" score="-INFINITY" symmetrical="false"/> /* Maximo application should not run on the node assigned to ITIC */ <rsc_colocation id="not_same_3" to="maximo_group" from="taddm_group" score="-INFINITY" symmetrical="false"/> /* Maximo application should not run on the node assigned eCMDB */ <rsc_colocation id="not_same_2" to="taddm_group" from="iticd_group" score="-INFINITY" symmetrical="false"/> /* eCMDB application should not run on the node assigned to ITIC */ <rsc_location id="location_maximo" rsc="maximo_group"> <rule id="prefered_location_maximo_1" score="20"> <expression attribute="#uname" operation="eq" value="hacluster2.svl.ibm.com" id="a4b1be4e-4c25-46a6-9237-60a3b7b44389"/> /* Spare node for Maximo should preferred node fail */ </rule> <rule id="prefered_location_maximo_2" score="100"> <expression attribute="#uname" operation="eq" value="hacluster1.svl.ibm.com" id="3ece30c7-0530-4b54-a21b-ace9b127d3e3"/> /* Preferred node for Maximo to run */ </rule> <rule id="prefered_location_maximo_3" score="-INFINITY"> <expression attribute="#uname" operation="eq" value="hacluster4.svl.ibm.com" id="7cb3b3e2-191f-492d-84f9-257b96c02c3c"/> /* Maximo cannot co-exist with eCMDB on this node */ </rule> <rule id="prefered_location_maximo_4" score="-INFINITY"> <expression attribute="#uname" operation="eq" value="hacluster3.svl.ibm.com" id="a78cce70-c717-4c33-910e-11cc39ded186"/> /* Maximo cannot co-exist with ITIC on this node */ </rule> </rsc_location> <rsc_location id="location_iticd" rsc="iticd_group"> <rule id="prefered_location_iticd_1" score="20"> <expression attribute="#uname" operation="eq" value="hacluster2.svl.ibm.com" id="e3de5eee-ee29-4e94-89d7-36fef3d76082"/> /* Spare node for ITIC should preferred node fail */ </rule> <rule id="prefered_location_iticd_2" score="100"> <expression attribute="#uname" operation="eq" value="hacluster3.svl.ibm.com" id="f8153d3d-f821-46e3-b41d-7e869e2960ec"/> /* Preferred node for ITIC to run */ </rule> <rule id="prefered_location_iticd_3" score="-INFINITY"> <expression attribute="#uname" operation="eq" value="hacluster1.svl.ibm.com" id="7b7e7ec4-1381-47fb-afdf-732c4b180ba6"/> /* ITIC cannot co-exist with Maximo on this node */ </rule> <rule id="prefered_location_iticd_4" score="-INFINITY"> <expression attribute="#uname" operation="eq" value="hacluster4.svl.ibm.com" id="1fd82c28-982b-462e-b147-6726d655a87f"/> /* ITIC cannot co-exist with eCMDB on this node */ </rule> </rsc_location> <rsc_location id="location_taddm" rsc="taddm_group"> <rule id="prefered_location_taddm_1" score="20"> <expression attribute="#uname" operation="eq" value="hacluster2.svl.ibm.com" id="b029d8a7-5a40-481f-8ebc-1168d6d76efa"/> /* Spare node for eCMDB should preferred node fail */ </rule> <rule id="prefered_location_taddm_2" score="100"> <expression attribute="#uname" operation="eq" value="hacluster4.svl.ibm.com" id="2cdf690e-e9c7-464e-9148-21be25565161"/> /* Preferred node for eCMDB to run */ </rule> <rule id="prefered_location_taddm_3" score="-INFINITY"> <expression attribute="#uname" operation="eq" value="hacluster1.svl.ibm.com" id="a3065c9e-e253-4890-879f-9cf143d82fed"/> /* eCMDB cannot co-exist with Maximo on this node */ </rule> <rule id="prefered_location_taddm_4" score="-INFINITY"> <expression attribute="#uname" operation="eq" value="hacluster3.svl.ibm.com" id="dfd2f607-a322-483d-af67-b33b6ba3556d"/> /* eCMDB cannot co-exist with ITIC on this node */ </rule> </rsc_location> </constraints> </configuration> </cib> </code> |
|
測試場景
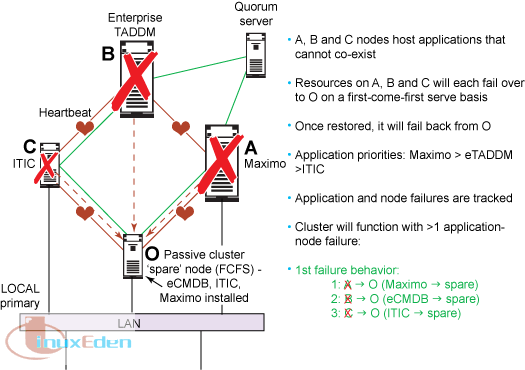
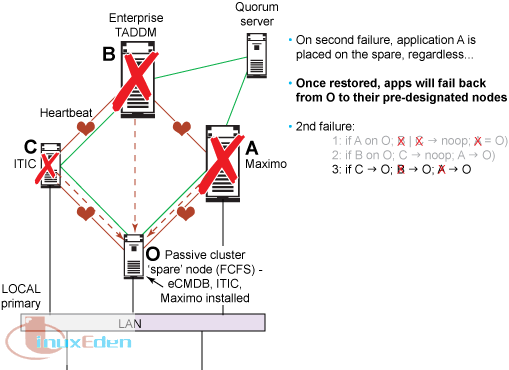
我們在此處使用的示例是一個包含 3 個應用程序、3 個節點的系統,其中包含一個空閑節點。對於上述演算法,我們使用包含 4 台機器的集群,其中包括 Maximo、eCMDB(Enterprise TADDM 伺服器的簡稱)、IC(Integration Composer 的簡稱)以及一個被動空閑機器,所有機器都具有相同的硬體智能特性。為遠程站點提供類似的 4 台機器。被動空閑機器可以運行任何 Maximo、eCMDB 或 IC 應用程序。我們採用的演算法遵循以下邏輯路徑:
我們只需為 3 個不同的應用程序提供一個空閑節點。這些應用程序擁有內置的優先順序。儘管所有 3 個應用程序都期望擁有高可用性,但是該可用性擁有先後次序,並且所有機器和應用程序都必須遵循這個順序。
如果我們擁有一個必須全天候可用的應用程序,而其他應用程序沒有嚴格的 HA 需求,那麼我們至少需要一個空閑節點。如果我們擁有兩台具有相同的 HA 配置文件的機器,那麼我們需要兩個空閑節點,依此類推。如果空閑節點上不能同時存在多個應用程序,那麼所有指定的條件都為真。也就是說,將 3 個應用程序安裝在同一台(空閑)機器上不會造成衝突。圖 1 給出了一個包含 3 個應用程序、4 個節點的集群的示例。右側圖片是左側圖片的鏡像,用於災難恢復。這個鏡像僅在左側的所有 4 台機器都宕機之後才使用。
在下表中,Maximo (= A)、eCMDB (= B) 和 ITIC (= C) 在獨立的機器上運行。我們忽略了機器名稱,因為它們無關緊要,每台機器代表在其上運行的應用程序。
這些機器不運行其他任何重要的應用程序,但是指定的應用程序除外。被動空閑機器 (= O) 安裝了 Maximo、eCMDB 和 ITIC,但是僅支持一個應用程序處於執行模式。
記住,在我們的 HA 設計中,應用程序優先順序為 Maximo > eCMDB > ITIC,O 是指定的協調程序(空閑節點)。
| 出現故障的應用程序 | 第一次故障之後的應用程序配置 |
|---|---|
| A | A => O; B; C |
| B | A; B => O; C |
| C | A; B; C => O |
| O | 無策略 |
| 出現第一次故障的機器 | 第二次故障之前的配置 | 第二次故障 | 第二次故障之後的配置 |
|---|---|---|---|
| A | A => O; B; C | B | A = O; B unavail; C; |
| C | A = O; B; C unavail | ||
| B | A; B => O; C | A | B exits; A => O; C; B unavail |
| C | A; B = O; C unavail | ||
| C | A; B; C => O | A | C exits; A => O; B; C unavail |
| B | C exits; A; B => O; C unavail |
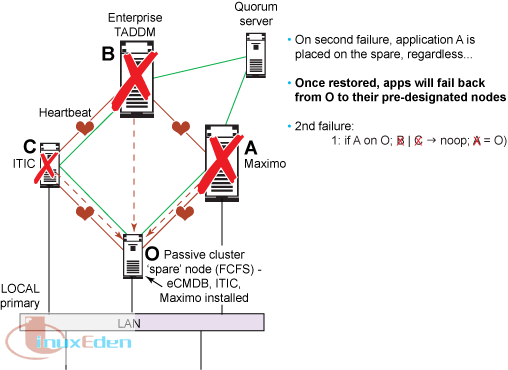
對於第二次故障,情形 1:如果 A 出現故障,它將被轉移到空閑節點上。如果接下來 ITIC 或 eCMDB 出現故障,那麼將不會發生任何事件。Maximo 將一直可在空閑節點上使用。
對於第二次故障,情形 2:如果 eCMDB 位於空閑節點上,那麼 ITIC 隨後出現故障時將不會更改現狀,但是 Maximo 將從空閑節點上轉儲 eCMDB。
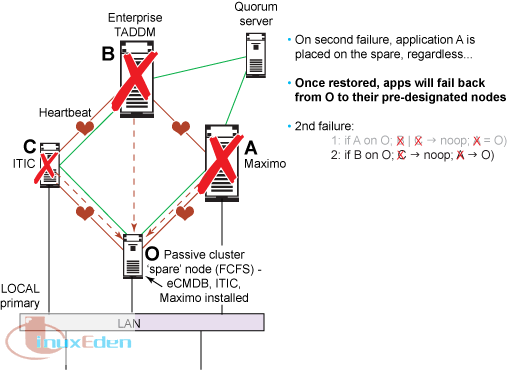
對於第二次故障,情形 3:如果 ITIC 位於空閑節點上,那麼 eCMDB 在隨後出現故障時將從所在位置轉儲 ITIC。如果接下來 Maximo 出現故障,那麼它將從空閑節點轉儲 eCMDB。如果集群中只有空閑節點可用,那麼 Maximo 將是惟一運行的應用程序。
實現小結
該實現遵循以下規則:
災難恢復
遠程站點上的規則完全相同,但是沒有應用程序處於運行狀態。只會從原始位置複製到公共的外部磁碟。發生站點故障轉移之後,執行流程為:
|
結束語
本文描述了使用 Linux-HA 完成的複合應用程序的 HA 實現,它基於我們在客戶需求方面的豐富經驗。我們的 HA 任務涉及同一集群中具有不同優先順序的多個應用程序。也許為每個應用程序添加一個空閑節點會更簡單,但是這種解決方案成本較高。對於大多數真實的 HA 應用程序,您必須適應實際存在的經濟條件和冗餘,它們通常是相互排斥的。 (責任編輯:A6)
[火星人 ] 實現複合應用程序的高可用性已經有714次圍觀
