Google Spanner簡介
Spanner 是Google的全球級的分散式資料庫 (Globally-Distributed Database) 。Spanner的擴展性達到了令人咋舌的全球級,可以擴展到數百萬的機器,數已百計的數據中心,上萬億的行。更給力的是,除了誇張的擴展性之外,他還能同時通過同步複製和多版本來滿足外部一致性,可用性也是很好的。衝破CAP的枷鎖,在三者之間完美平衡。
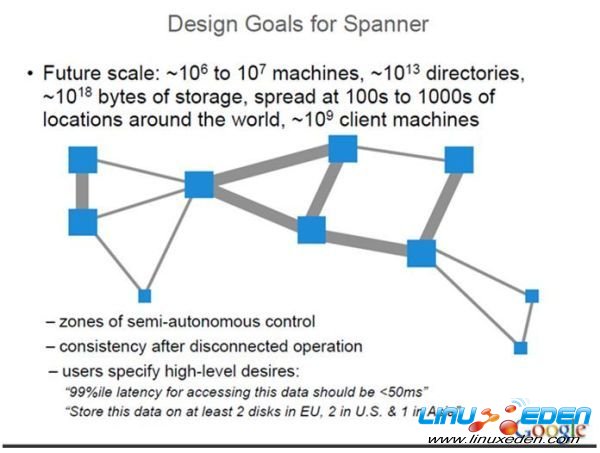
Spanner是個可擴展,多版本,全球分散式還支持同步複製的資料庫。他是Google的第一個可以全球擴展並且支持外部一致的事務。Spanner能做到這些,離不開一個用GPS和原子鐘實現的時間API。這個API能將數據中心之間的時間同步精確到10ms以內。因此有幾個給力的功能:無鎖讀事務,原子schema修改,讀歷史數據無block。
EMC中國研究院實時緊盯業界動態,Google最近發布的一篇論文《Spanner: Google’s Globally-Distributed Database》, 筆者非常感興趣,對Spanner進行了一些調研,並在這裡分享。由於Spanner並不是開源產品,筆者的知識主要來源於Google的公開資料,通過現有公開資料僅僅只能窺得Spanner的滄海一粟,Spanner背後還依賴有大量Google的專有技術。
下文主要是Spanner的背景,設計和併發控制。
Spanner背景
要搞清楚Spanner原理,先得了解Spanner在Google的定位。
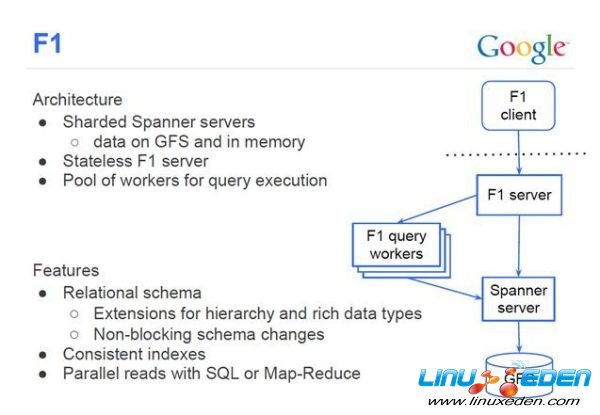
從上圖可以看到。Spanner位於F1和GFS之間,承上啟下。所以先提一提F1和GFS。
F1
和眾多互聯網公司一樣,在早期Google大量使用了Mysql。Mysql是單機的,可以用Master-Slave來容錯,分區來擴展。但是需要大量的手工運維工作,有很多的限制。因此Google開發了一個可容錯可擴展的RDBMS——F1。和一般的分散式資料庫不同,F1對應RDMS應有的功能,毫不妥協。起初F1是基於Mysql的,不過會逐漸遷移到Spanner。
F1有如下特點:
· 7×24高可用。哪怕某一個數據中心停止運轉,仍然可用。
· 可以同時提供強一致性和弱一致。
· 可擴展
· 支持SQL
· 事務提交延遲50-100ms,讀延遲5-10ms,高吞吐
眾所周知Google BigTable是重要的NoSQL產品,提供很好的擴展性,開源世界有HBase與之對應。為什麼Google還需要F1,而不是都使用BigTable呢?因為BigTable提供的最終一致性,一些需要事務級別的應用無法使用。同時BigTable還是NoSql,而大量的應用場景需要有關係模型。就像現在大量的互聯網企業都使用Mysql而不願意使用HBase,因此Google才有這個可擴展資料庫的F1。而Spanner就是F1的至關重要的底層存儲技術。
Colossus(GFS II)
Colossus也是一個不得不提起的技術。他是第二代GFS,對應開源世界的新HDFS。GFS是著名的分散式文件系統。
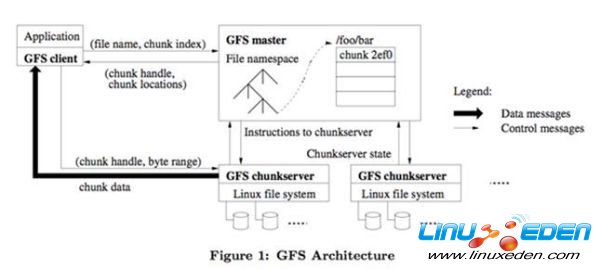
初代GFS是為批處理設計的。對於大文件很友好,吞吐量很大,但是延遲較高。所以使用他的系統不得不對GFS做各種優化,才能獲得良好的性能。那為什麼Google沒有考慮到這些問題,設計出更完美的GFS ?因為那個時候是2001年,Hadoop出生是在2007年。如果Hadoop是世界領先水平的話,GFS比世界領先水平還領先了6年。同樣的Spanner出生大概是2009年,現在我們看到了論文,估計Spanner在Google已經很完善,同時Google內部已經有更先進的替代技術在醞釀了。筆者預測,最早在2015年才會出現Spanner和F1的山寨開源產品。
Colossus是第二代GFS。Colossus是Google重要的基礎設施,因為他可以滿足主流應用對FS的要求。Colossus的重要改進有:
· 優雅Master容錯處理 (不再有2s的停止服務時間)
· Chunk大小隻有1MB (對小文件很友好)
· Master可以存儲更多的Metadata(當Chunk從64MB變為1MB后,Metadata會擴大64倍,但是Google也解決了)
Colossus可以自動分區Metadata。使用Reed-Solomon演算法來複制,可以將原先的3份減小到1.5份,提高寫的性能,降低延遲。客戶端來複制數據。具體細節筆者也猜不出。
與BigTable, Megastore對比
Spanner主要致力於跨數據中心的數據複製上,同時也能提供資料庫功能。在Google類似的系統有BigTable和Megastore。和這兩者相比,Spanner又有什麼優勢呢。
BigTable在Google得到了廣泛的使用,但是他不能提供較為複雜的Schema,還有在跨數據中心環境下的強一致性。Megastore有類RDBMS的數據模型,同時也支持同步複製,但是他的吞吐量太差,不能適應應用要求。Spanner不再是類似BigTable的版本化 key-value存儲,而是一個“臨時多版本”的資料庫。何為“臨時多版本”,數據是存儲在一個版本化的關係表裡面,存儲的時間數據會根據其提交的時間打上時間戳,應用可以訪問到較老的版本,另外老的版本也會被垃圾回收掉。
Google官方認為 Spanner是下一代BigTable,也是Megastore的繼任者。
Google Spanner設計
功能
從高層看Spanner是通過Paxos狀態機將分區好的數據分佈在全球的。數據複製全球化的,用戶可以指定數據複製的份數和存儲的地點。Spanner可以在集群或者數據發生變化的時候將數據遷移到合適的地點,做負載均衡。用戶可以指定將數據分佈在多個數據中心,不過更多的數據中心將造成更多的延遲。用戶需要在可靠性和延遲之間做權衡,一般來說複製1,2個數據中心足以保證可靠性。
作為一個全球化分散式系統,Spanner提供一些有趣的特性。
· 應用可以細粒度的指定數據分佈的位置。精確的指定數據離用戶有多遠,可以有效的控制讀延遲(讀延遲取決於最近的拷貝)。指定數據拷貝之間有多遠,可以控制寫的延遲(寫延遲取決於最遠的拷貝)。還要數據的複製份數,可以控制數據的可靠性和讀性能。(多寫幾份,可以抵禦更大的事故)
· Spanner還有兩個一般分散式資料庫不具備的特性:讀寫的外部一致性,基於時間戳的全局的讀一致。這兩個特性可以讓Spanner支持一致的備份,一致的MapReduce,還有原子的Schema修改。
這些特性都得益有Spanner有一個全球時間同步機制,可以在數據提交的時候給出一個時間戳。因為時間是系列化的,所以才有外部一致性。這個很容易理解,如果有兩個提交,一個在T1,一個在T2。那有更晚的時間戳那個提交是正確的。
這個全球時間同步機制是用一個具有GPS和原子鐘的TrueTime API提供了。這個TrueTime API能夠將不同數據中心的時間偏差縮短在10ms內。這個API可以提供一個精確的時間,同時給出誤差範圍。Google已經有了一個TrueTime API的實現。筆者覺得這個TrueTimeAPI 非常有意義,如果能單獨開源這部分的話,很多資料庫如MongoDB都可以從中受益。
體系結構
Spanner由於是全球化的,所以有兩個其他分散式資料庫沒有的概念。
· Universe。一個Spanner部署實例稱之為一個Universe。目前全世界有3個。一個開發,一個測試,一個線上。因為一個Universe就能覆蓋全球,不需要多個。
· Zones. 每個Zone相當於一個數據中心,一個Zone內部物理上必須在一起。而一個數據中心可能有多個Zone。可以在運行時添加移除Zone。一個Zone可以理解為一個BigTable部署實例。
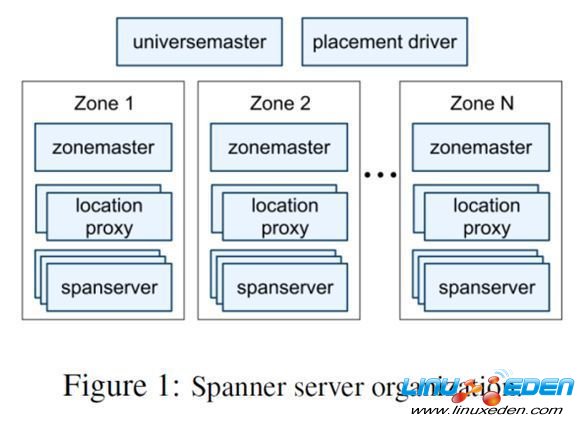
如圖所示。一個Spanner有上面一些組件。實際的組件肯定不止這些,比如TrueTime API Server。如果僅僅知道這些知識,來構建Spanner是遠遠不夠的。但Google都略去了。那筆者就簡要介紹一下。
· Universemaster: 監控這個universe里zone級別的狀態信息
· Placement driver:提供跨區數據遷移時管理功能
· Zonemaster:相當於BigTable的Master。管理Spanserver上的數據。
· Location proxy:存儲數據的Location信息。客戶端要先訪問他才知道數據在那個Spanserver上。
· Spanserver:相當於BigTable的ThunkServer。用於存儲數據。
可以看出來這裡每個組件都很有料,但是Google的論文里只具體介紹了Spanserver的設計,筆者也只能介紹到這裡。下面詳細闡述Spanserver的設計。
Spanserver
本章詳細介紹Spanserver的設計實現。Spanserver的設計和BigTable非常的相似。參照下圖:
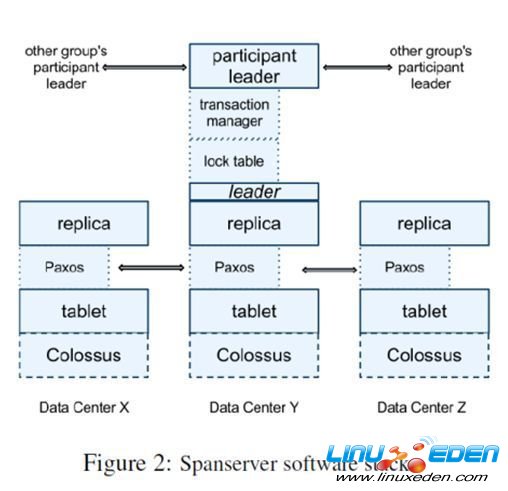
從下往上看。每個數據中心會運行一套Colossus (GFS II) 。每個機器有100-1000個tablet。Tablet概念上將相當於資料庫一張表裡的一些行,物理上是數據文件。打個比方,一張1000行的表,有10個tablet,第1-100行是一個tablet,第101-200是一個tablet。但和BigTable不同的是BigTable裡面的tablet存儲的是Key-Value都是string,Spanner存儲的Key多了一個時間戳:
(Key: string, timestamp: int64) ->string。
因此spanner天生就支持多版本,tablet在文件系統中是一個B-tree-like的文件和一個write-ahead日誌。
每個Tablet上會有一個Paxos狀態機。Paxos是一個分散式一致性協議。Table的元數據和log都存儲在上面。Paxos會選出一個replica做leader,這個leader的壽命默認是10s,10s后重選。Leader就相當於複製數據的master,其他replica的數據都是從他那裡複製的。讀請求可以走任意的replica,但是寫請求只有去leader。這些replica統稱為一個paxos group。
每個leader replica的spanserver上會實現一個lock table還管理併發。Lock table記錄了兩階段提交需要的鎖信息。但是不論是在Spanner還是在BigTable上,但遇到衝突的時候長時間事務會將性能很差。所以有一些操作,如事務讀可以走lock table,其他的操作可以繞開lock table。
每個leader replica的spanserver上還有一個transaction manager。如果事務在一個paxos group裡面,可以繞過transaction manager。但是一旦事務跨多個paxos group,就需要transaction manager來協調。其中一個Transactionmanager被選為leader,其他的是slave聽他指揮。這樣可以保證事務。
Directories and Placement
之所以Spanner比BigTable有更強的擴展性,在於Spanner還有一層抽象的概念directory, directory是一些key-value的集合,一個directory裡面的key有一樣的前綴。更妥當的叫法是bucketing。Directory是應用控制數據位置的最小單元,可以通過謹慎的選擇Key的前綴來控制。據此筆者可以猜出,在設計初期,Spanner是作為F1的存儲系統而設立,甚至還設計有類似directory的層次結構,這樣的層次有很多好處,但是實現太複雜被摒棄了。
Directory作為數據放置的最小單元,可以在paxos group裡面移來移去。Spanner移動一個directory一般出於如下幾個原因:
· 一個paxos group的負載太大,需要切分
· 將數據移動到access更近的地方
· 將經常同時訪問的directory放到一個paxos group裡面
Directory可以在不影響client的前提下,在後台移動。移動一個50MB的directory大概需要的幾秒鐘。
那麼directory和tablet又是什麼關係呢。可以理解為Directory是一個抽象的概念,管理數據的單元;而tablet是物理的東西,數據文件。由於一個Paxos group可能會有多個directory,所以spanner的tablet實現和BigTable的tablet實現有些不同。BigTable的tablet是單個順序文件。Google有個項目,名為Level DB,是BigTable的底層,可以看到其實現細節。而Spanner的tablet可以理解是一些基於行的分區的容器。這樣就可以將一些經常同時訪問的directory放在一個tablet裡面,而不用太在意順序關係。
在paxos group之間移動directory是後台任務。這個操作還被用來移動replicas。移動操作設計的時候不是事務的,因為這樣會造成大量的讀寫block。操作的時候是先將實際數據移動到指定位置,然後再用一個原子的操作更新元數據,完成整個移動過程。
Directory還是記錄地理位置的最小單元。數據的地理位置是由應用決定的,配置的時候需要指定複製數目和類型,還有地理的位置。比如(上海,複製2份;南京複製1分) 。這樣應用就可以根據用戶指定終端用戶實際情況決定的數據存儲位置。比如中國隊的數據在亞洲有3份拷貝, 日本隊的數據全球都有拷貝。
前面對directory還是被簡化過的,還有很多無法詳述。
數據模型
Spanner的數據模型來自於Google內部的實踐。在設計之初,Spanner就決心有以下的特性:
· 支持類似關係資料庫的schema
· Query語句
· 支持廣義上的事務
為何會這樣決定呢?在Google內部還有一個Megastore,儘管要忍受性能不夠的折磨,但是在Google有300多個應用在用它,因為Megastore支持一個類似關係資料庫的schema,而且支持同步複製 (BigTable只支持最終一致的複製) 。使用Megastore的應用有大名鼎鼎的Gmail, Picasa, Calendar, Android Market和AppEngine。 而必須對Query語句的支持,來自於廣受歡迎的Dremel,筆者不久前寫了篇文章來介紹他。 最後對事務的支持是比不可少了,BigTable在Google內部被抱怨的最多的就是其只能支持行事務,再大粒度的事務就無能為力了。Spanner的開發者認為,過度使用事務造成的性能下降的惡果,應該由應用的開發者承擔。應用開發者在使用事務的時候,必須考慮到性能問題。而資料庫必須提供事務機制,而不是因為性能問題,就乾脆不提供事務支持。
數據模型是建立在directory和key-value模型的抽象之上的。一個應用可以在一個universe中建立一個或多個database,在每個database中建立任意的table。Table看起來就像關係型資料庫的表。有行,有列,還有版本。Query語句看起來是多了一些擴展的SQL語句。
Spanner的數據模型也不是純正的關係模型,每一行都必須有一列或多列組件。看起來還是Key-value。主鍵組成Key,其他的列是Value。但這樣的設計對應用也是很有裨益的,應用可以通過主鍵來定位到某一行。
[火星人 ] Google全球級分散式資料庫Spanner原理已經有1642次圍觀
