前言
關於group by 與distinct 性能對比:網上結論如下,不走索引少量數據distinct性能更好,大數據量group by 性能好,走索引group by性能好。走索引時分組種類少distinct快。關於網上的結論做一次驗證。
準備階段屏蔽查詢緩存
查看MySQL中是否設置了查詢緩存。為了不影響測試結果,需要關閉查詢緩存。
show variables like '%query_cache%';

查看是否開啟查詢緩存決定於 query_cache_type 和 query_cache_size 。
方法一:關閉查詢緩存需要找到my.ini,修改 query_cache_type 需要修改C:ProgramDataMySQLMySQL Server 5.7my.ini配置文件,修改 query_cache_type=0或2 。
方法二:設置 query_cache_size 為0,執行以下語句。
set global query_cache_size = 0;
方法三:如果你不想關閉查詢緩存,也可以在使用 RESET QUERY CACHE 。
現在測試環境中query_cache_type=2代表按需進行查詢緩存,默認的查詢方式是不會進行緩存,如需緩存則需要在查詢語句中加上 sql_cache 。
數據準備
t0表存放10W 少量種類少 的數據
drop table if exists t0; create table t0( id bigint primary key auto_increment, a varchar(255) not null ) engine=InnoDB default charset=utf8mb4 collate=utf8mb4_bin; 1 2 3 4 5 drop procedure insert_t0_simple_category_data_sp; delimiter // create procedure insert_t0_simple_category_data_sp(IN num int) begin set @i = 0; while @i<num do insert into t0(a) value(truncate(@i/1000, 0)); set @i = @i + 1; end while; end // call insert_t0_simple_category_data_sp(100000);
t1表存放1W 少量種類多 的數據
drop table if exists t1; create table t1 like t0; 1 2 drop procedure insert_t1_complex_category_data_sp; delimiter // create procedure insert_t1_complex_category_data_sp(IN num int) begin set @i = 0; while @i<num do insert into t1(a) value(truncate(@i/10, 0)); set @i = @i + 1; end while; end // call insert_t1_complex_category_data_sp(10000);
t2表存放500W 大量種類多 的數據
drop table if exists t2; create table t2 like t1; 1 2 drop procedure insert_t2_complex_category_data_sp; delimiter // create procedure insert_t2_complex_category_data_sp(IN num int) begin set @i = 0; while @i<num do insert into t1(a) value(truncate(@i/10, 0)); set @i = @i + 1; end while; end // call insert_t2_complex_category_data_sp(5000000);
測試階段
驗證少量種類少數據
未加索引
set profiling = 1; select distinct a from t0; show profiles; select a from t0 group by a; show profiles; alter table t0 add index `a_t0_index`(a);

由此可見:少量種類少數據下,未加索引,distinct和group by性能相差無幾。
加索引
alter table t0 add index `a_t0_index`(a);
執行上述類似查詢後

由此可見:少量種類少數據下,加索引,distinct和group by性能相差無幾。
驗證少量種類多數據未加索引
執行上述類似未加索引查詢後

由此可見:少量種類多數據下,未加索引,distinct比group by性能略高,差距並不大。
加索引
alter table t1 add index `a_t1_index`(a);
執行類似未加索引查詢後

由此可見:少量種類多數據下,加索引,distinct和group by性能相差無幾。
驗證大量種類多數據
未加索引
SELECT count(1) FROM t2;

執行上述類似未加索引查詢後
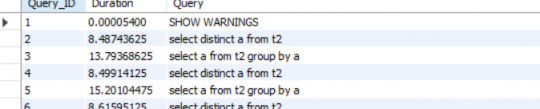
由此可見:大量種類多數據下,未加索引,distinct比group by性能高。
加索引
alter table t2 add index `a_t2_index`(a);
執行上述類似加索引查詢後

由此可見:大量種類多數據下,加索引,distinct和group by性能相差無幾。
總結
性能比少量種類少少量種類多大量種類多未加索引相差無幾distinct略優distinct更優加索引相差無幾相差無幾相差無幾
去重場景下,未加索引時,更偏向於使用distinct,而加索引時,distinct和group by兩者都可以使用。
[techdo ] MySQL去重該使用distinct還是group by?已經有258次圍觀
