前言
本文的內容是總結一些MySQL的常見使用技巧,以供沒有DBA的團隊參考。如無特殊說明,存儲引擎以InnoDB為準。
MySQL的特點
瞭解MySQL的特點有助於更好的使用MySQL,MySQL和其它常見數據庫最大的不同在於存在存儲引擎這個概念,存儲引擎負責存儲和讀取數據。不同的存儲引擎具有不同的特點,用戶可以根據業務的特點選擇適合的存儲引擎,甚至是開發一個新的引擎。MySQL的邏輯架構大致如下:
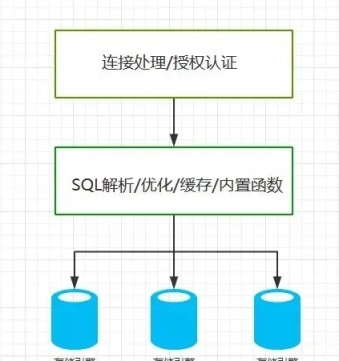
MySQL默認的存儲引擎是InnoDB,該存儲引擎的主要特點是:
支持事務處理
支持行級鎖
數據存儲在表空間中,表空間由一些列數據文件組成
採用MVVC(多版本併發控制)機制實現高併發
表基於主鍵的聚簇索引建立
支持熱備份
其它常見存儲引擎特點概述:
MyISAM:老版本MySQL的默認引擎,不支持事務和行級鎖,開發者可以手動控制表鎖;支持全文索引;崩潰後無法安全恢復;支持壓縮表,壓縮表數據不可修改,但佔用空間較少,可以提高查詢性能
Archive:只支持Insert和Select,批量插入很快,通過全表掃描查詢數據
SCV:把一個SCV文件當做一個表處理
Memory:數據存儲在內存中
還有很多,不再一一列舉。
數據類型優化
選擇數據類型的原則:
選擇佔用空間小的數據類型
選擇簡單的類型
避免不必要的可空列
佔用空間小的類型更節省硬件資源,如磁盤、內存和CPU。儘量使用簡單的類型,如能用 int 就不用 char ,因為後者的排序涉及到字符集的選擇,比使用 int 複雜。可空列使用更多的存儲空間,如果在可空列上創建索引,MySQL需要額外的字節做記錄。創建表時,默認都是可空,容易被開發者忽視,最好是手動改為不可空,如果要存儲的數據確實不會有空值的話。
整型類型
整型類型包括 :
tinyint
smallint
mediumint
int
bigint
它們分別使用8、16、24、32和64位存儲數字,它們可以表示
範圍的數字,前面可以加unsigned修飾,這樣可以讓正數的可表示範圍提高1倍,但是無法表示負數。另外,為整型指定長度沒什麼卵用,數據類型定下來,長度也就相應定下來了。
小數類型
float
double
decimal
float 和 double 就是通常意義上的 float 和 double ,前者使用32位存儲數據,後者使用64位存儲數據,和整型一樣,為它們指定長度沒什麼卵用。
decimal 類型比較複雜,支持精確計算,佔用的空間也大, decimal 使用每4個字節表示9個數字,如 decimal(18,9) 表示數字長度是18,其中小數位9個數字,整數部分9個數字,加上小數點本身,共佔用9個字節。考慮到 decimal 佔用空間較多,以及精度計算很複雜,數據量大的時候可以考慮用 bigint 代替之,可以在持久化和讀取前對真實數據進行一些縮放操作。
字符串類型
varchar
char
varbinary
binary
blob
text
枚舉
varchar類型數據實際佔用空間等於字符串的長度加上1個或2個用來記錄字符串長度的字節(當row-format沒有被設置為fixed時),varchar很節省空間。當表中某列字符串類型的數據長度差別較大時適合使用varchar。
char的實際佔用空間是固定的,當表中字符串數據的長度相差無幾或很短時適合使用chart類型。
與varchar和char對應的有varbinary和binary,後者存儲的是二進制字符串,和前者相比,後者大小寫敏感,不用考慮編碼方式,執行比較操作時更快。
需要注意的是:雖然varchar(5)和varchar(200)在存儲“hello”這個字符串時使用相同的存儲空間,但並不意味著將varchar的長度設置太大不會影響性能,實際上,MySQL的某些內部計算,比如創建內存臨時表時(某些查詢會導致MySQL自動創建臨時表),會分配固定大小的空間存放數據。
blob使用二進制字符串保存大文本,text使用字符保存大文本,InnoDB會使用專門的外部存儲區來存放此類數據,數據行內僅存放指向他們的指針,此類數據不宜創建索引(要創建也只能正對字符串前綴創建),不過也不會有人這麼幹。
如果某列字符串大量重複且內容有限,可使用枚舉代替,MySQL處理枚舉時維護了一個“數字-字符串”表,使用枚舉可以減少很多存儲空間。
時間類型
year
date
time
datetime
timestamp
datetime存儲範圍是1001到9999,精確到秒。timestamp存儲1970年1月1日午夜以來的秒數,可以表示到2038年。佔用4個字節,是datetime佔用空間的一半。timestamp表示的時間和時區有關,另外timestamp列還有個特性,執行insert或update語句時,MySQL會自動更新第一個類型為timestamp的列的數據為當前時間。很多表中都有設計有一列叫做UpdateTime,這個列使用timestamp倒是挺合適的,會自動更新,前提是系統不會使用到2038年。
主鍵類型的選擇
儘可能使用整型,整型佔用空間少,還可以設置為自動增長。尤其別使用GUID,MD5等哈希值字符串作為主鍵,這類字符串隨機性很大,由於InnoDB主鍵默認是聚簇索引列,所以導致數據存儲太分散。另外,InnoDB的二級索引列中默認包含主鍵列,如果主鍵太長,也會使得二級索引很佔空間。
特殊類型的數據
存儲IP最好使用32位無符號整型,MySQL提供了函數inet_aton()和inet_ntoa()進行IP地址的數字表示和字符串表示之間的轉換。
索引優化
InnoDB使用B+樹實現索引,舉個例子,假設有個People,建表語句如下
CREATE TABLE `people` ( `Id` int(11) NOT NULL AUTO_INCREMENT, `Name` varchar(5) NOT NULL, `Age` tinyint(4) NOT NULL, `Number` char(5) NOT NULL COMMENT '編號', PRIMARY KEY (`Id`), KEY `i_name_age_number` (`Name`,`Age`,`Number`) ) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
插入數據:
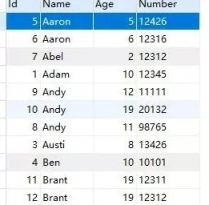
它的索引結構大致是這樣的:

也就是說,索引列的順序很重要,如果兩行數據的Name列相同,則用Age列比較大小,如果Age列相同,則用Number列比較大小。先用第一列排序,然後是第二列,最後是第三列。
查詢的使用應該儘量從左往右匹配,另外,如果左邊列範圍查找,右邊列無法使用索引;還有就是不能隔列查詢,否則後面的索引也無法使用到。如以下幾個SQL是正面範例:
SELECT * from people where Name ='Abel' and Age = 2 AND Number = 12312
SELECT * from people where Name ='Abel'
SELECT * from people where Name like ‘Abel%'
SELECT * from people where Name = ‘Andy' and Age BETWEEN 11 and 20
SELECT * from people ORDER BY NAME
SELECT * from people ORDER BY NAME, Age
SELECT * from people GROUP BY Name
以下幾個SQL是反面範例:
SELECT * from people where Age = 2
SELECT * from people where NAME like ‘%B'
SELECT * from people where age = 2
SELECT * from people where NAME = ‘ABC' AND number = 3
SELECT * from people where NAME like ‘B%' and age = 22
一個使用Hash值創建索引的技巧
如果表中有一列存儲較長字符串,假設名字為URL,在此列上創建的索引比較大,有個辦法可以緩解:創建URL字符串的數字哈希值的索引。再新建一個字段,比如叫做URL_CRC,專門放置URL的哈希值,然後給這個字段創建索引,查詢時這樣寫:
select * from t where URL_CRC = 387695885 and URL = 'www.baidu.com'
如果數據量比較多,為防止哈希衝突,可自定義哈希函數,或用MD5函數返回值的一部分作為哈希值:
SELECT CONV(RIGHT(MD5('www.baidu.com'),16), 16, 10)
前綴索引
如果字符串列存儲的數據較長,創建的索引也很大,這時可以使用前綴索引,即:只針對字符串前幾個字符做索引,這樣可以縮短索引的大小,不過,顯然,此類索引在執行 order by 和 group by 時不起作用。
創建前綴索引時選擇前綴長度很重要,在不破壞原來數據分佈的情況下儘可能選擇較短的前綴。舉個例子,如果如果大部分字符串是以”abc”開頭,那麼如果限定前綴索引長度為4,索引值會包含太多的重複的”abcX”。
多列索引
上面提到的“People”上創建的索引即為多列索引,多列索引往往比多個單列索引更好。
對多個索引進行and查詢時,應該創建多列索引,而不是多個單列索引
可以試試這樣寫的效果:
select * from t where f1 = 'v1' and f2 <> 'v2' union all select * from t where f2 = 'v2' and f1 <> 'v1'
多列索引的順序很重要,通常,不考慮排序和分組查詢時,應該把選擇性(選擇性是指某表索引列不同數據的個數/總行數。選擇性高意味著重複數據少)大的列放到前面。但也有例外,如果能確認某些查詢是頻繁執行的,則應該優先照顧這些查詢的選擇性,比如,如果上面的People表中Name的選擇性大於Age,查詢語句應該這樣寫:
select * from people where name = 'xxx' and age = xx
Name列放了索引中的左側比較合適,但是如果某個SQL執行的評率最高,比如
select * from people where name = 'xxx' and age = 20
當age=20的記錄在數據庫中非常少時,反而把age放到索引列的左端效率更高。把age放了索引左端可能對其它age不等於20的查詢來說不公平,如果不能確定age=20是最非常頻繁的查詢條件,還是要綜合考慮,把name放了左側合適。
聚簇索引
聚簇索引是一種數據存儲結構,InnoDB在主鍵的索引的葉子節點中直接保存了數據行,而不是像二級索引那樣只是保存了索引列的值和所指向行的主鍵值。由於這個特性,一個表只能有一個聚簇索引。如果一個表沒有定義主鍵也沒有定義具有唯一索引的列,那麼InnoDB會生成一個隱藏列,並且在此列設為聚簇索引列。
覆蓋索引
簡單地說,某些查詢只需要查詢索引列,那麼就不用再根據索引B樹節點記錄的主鍵ID進行二次查詢了。
重複索引和冗餘索引
如果重複在某列創建索引,並不會帶來任何好處,只有壞處,應該儘量避免。比如給主鍵創建唯一索引和普通索引就是多於的,因為InnoDB的主鍵默認就是聚簇索引了。
冗餘索引和重複索引不同,比如某個索引是(A,B),另一個索引是(A),這叫冗餘索引,前者可以代替後者,後者不可以代替前者的作用。但是(A,B)和(B)以及(A,B)和(B,A)不算冗餘索引,起作用誰也代替不了誰。
如果一個表中已經存在索引(A),現在又想創建索引(A,B),那麼只需擴展就的索引就可以,沒有必要創建新的索引。需要注意的是如果已經存在索引(A),那麼也沒有必要在創建索引(A,ID),其中ID指主鍵,因為索引A默認已經包含了主鍵了,也算是冗餘主鍵。
但是,有時候,冗餘索引也是可取的,假設已經存在索引(A),將其擴展為(A,B)後,因為B列是一個很長的類型,導致用A單獨查詢時沒有以前快了,這時可以考慮新創建索引(A,B)。
不使用的索引
不使用的索引徒然增加insert、update和delete的效率,應該及時刪除
索引使用總結
索引的三星原則:
索引將查詢相關的記錄按順序放在一起則得一星
索引中的數據順序和查詢結果的排序一致則得一星
索引中包含了查詢所需要的全部列則得一星
第一個條原則的意思是where條件中查詢的順序和索引是一致的,就是前面說的從左到右使用索引。
索引不是萬能的,當數據量巨大時,維護索引本身也是耗費性能的,應該考慮分區分表存儲。
查詢優化
查詢慢的原因
是否向數據庫請求了多餘的行
比如應用程序只需要10條數據,但是卻向數據庫請求了所有的數據,在顯示在UI上之前拋棄了大部分數據。
是否向數據庫請求了多餘的列
比如應用程序只需要展現5列,但卻通過select * from 把全部的列都查了出來
是否重複多次執行了相同的查詢
應用程序是否可以考慮一次查詢然後緩存,後面的用到時可以使用第一次查詢出來的記錄。
MySQL是否在掃描額外的記錄
通過查看執行計劃可以大概瞭解需要掃描的記錄數,如果這個數字超出了預期,儘可能通過添加索引、優化SQL(就是本節的重點),或者改變表結構(如新增一個單獨的彙總表,專門供某個語句查詢用)來解決。
重構查詢的方式
將一個複雜的查詢分解成多個簡單的查詢
將大的查詢切分成小的查詢,每次查詢功能一樣,只完成一小部分
分解關聯查詢。可以將一個大的關聯查詢改成分別查詢若干個表,然後在應用程序代碼中處理
雜七雜八
優化count()
Count有兩個作用,一是統計指定的列或表達式,二是統計行數。如果參數傳入一列名或者是一個表達式,那麼count會統計所有結果不為NULL的行數,如果參數是*,那麼count會統計所有行數。這裡有一個傳表達式的例子:
SELECT count(name like 'B%') from people
可以使用近似值優化來代替count(),如執行計劃中的行數。
索引覆蓋掃描
增加彙總表
增加內存緩存系統記錄數據條數
關聯查詢的優化
MySQL優化器關聯表查詢是這樣進行的,比如有兩個表A和B通過c列關聯,MySQL會遍歷A表,然後根據遍歷到的c列的值去B表中查找數據。綜上所述,通常,如無只需要給B表的c列加上索引即可
確保order by和group by涉及到的列只屬於一個表,這樣才有可能發揮索引的作用
優化子查詢
對於MySQL5.5及以下版本,儘量用連接代替子查詢。
優化group by、distinct
如果可能,儘量對主鍵施加這兩種操作。
優化limit,比如有SQL
SELECT * from sa_stockinfo ORDER BY StockAcc LIMIT 400, 5
MySQL優化器會查找405行所有列數據然後丟棄400。如果能利用覆蓋索引查詢則不必查詢出這麼多列,先修改為:
SELECT * FROM sa_stockinfo i JOIN (SELECT StockInfoID FROM sa_stockinfo ORDER BY StockAcc LIMIT 400,5)t ON i.StockInfoID = t.StockInfoID
StockAcc上建有索引,該查詢會利用索引覆蓋,較快找出符合條件的主鍵,然後在做聯合查詢,在數據量大的時候效果明顯。
優化union
如無必要,一定要用關鍵字 union all,這樣MySQL把數據放到臨時表時不會再做唯一性驗證
判斷某條記錄是否存在,通常的做法是
select count(*) from t where condition
最好這樣寫:
SELECT IFNULL((SELECT 1 from tableName where condition LIMIT 1),0)
[lousu-xi ] 一篇文章掌握MySQL的索引查詢優化技巧已經有316次圍觀
