從github上轉來,實在是厲害的想法,什麼時候自己也能寫出這種精妙的代碼就好了
原地址:簡易高效的LeakyReLu實現
代碼如下:
我做了些改進,因為實在tensorflow中使用,就將原來的abs()函數替換成了tf.abs()
import tensorflow as tf def LeakyRelu(x, leak=0.2, name="LeakyRelu"): with tf.variable_scope(name): f1 = 0.5 * (1 + leak) f2 = 0.5 * (1 - leak) return f1 * x + f2 * tf.abs(x) # 這裡和原文有不一樣的,我沒試驗過原文的代碼,但tf.abs()肯定是對的
補充知識:激活函數ReLU、Leaky ReLU、PReLU和RReLU
“激活函數”能分成兩類――“飽和激活函數”和“非飽和激活函數”。
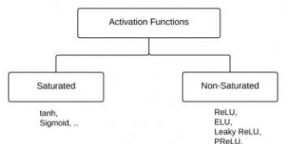
sigmoid和tanh是“飽和激活函數”,而ReLU及其變體則是“非飽和激活函數”。使用“非飽和激活函數”的優勢在於兩點:
1.首先,“非飽和激活函數”能解決所謂的“梯度消失”問題。
2.其次,它能加快收斂速度。
Sigmoid函數需要一個實值輸入壓縮至[0,1]的範圍
σ(x) = 1 / (1 + exp(−x))
tanh函數需要講一個實值輸入壓縮至 [-1, 1]的範圍
tanh(x) = 2σ(2x) − 1
ReLU
ReLU函數代表的的是“修正線性單元”,它是帶有卷積圖像的輸入x的最大函數(x,o)。ReLU函數將矩陣x內所有負值都設為零,其餘的值不變。ReLU函數的計算是在卷積之後進行的,因此它與tanh函數和sigmoid函數一樣,同屬於“非線性激活函數”。這一內容是由Geoff Hinton首次提出的。
ELUs
ELUs是“指數線性單元”,它試圖將激活函數的平均值接近零,從而加快學習的速度。同時,它還能通過正值的標識來避免梯度消失的問題。根據一些研究,ELUs分類精確度是高於ReLUs的。下面是關於ELU細節信息的詳細介紹:
Leaky ReLUs
ReLU是將所有的負值都設為零,相反,Leaky ReLU是給所有負值賦予一個非零斜率。Leaky ReLU激活函數是在聲學模型(2013)中首次提出的。以數學的方式我們可以表示為:
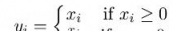
ai是(1,+∞)區間內的固定參數。
參數化修正線性單元(PReLU)
PReLU可以看作是Leaky ReLU的一個變體。在PReLU中,負值部分的斜率是根據數據來定的,而非預先定義的。作者稱,在ImageNet分類(2015,Russakovsky等)上,PReLU是超越人類分類水平的關鍵所在。
隨機糾正線性單元(RReLU)
“隨機糾正線性單元”RReLU也是Leaky ReLU的一個變體。在RReLU中,負值的斜率在訓練中是隨機的,在之後的測試中就變成了固定的了。RReLU的亮點在於,在訓練環節中,aji是從一個均勻的分佈U(I,u)中隨機抽取的數值。形式上來說,我們能得到以下結果:
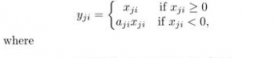
總結
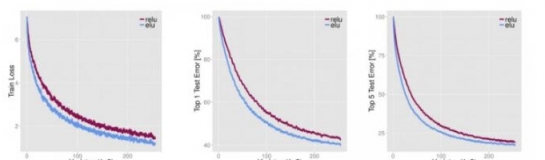
下圖是ReLU、Leaky ReLU、PReLU和RReLU的比較:
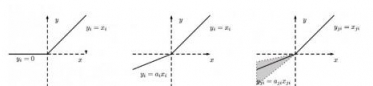
PReLU中的ai是根據數據變化的;
Leaky ReLU中的ai是固定的;
RReLU中的aji是一個在一個給定的範圍內隨機抽取的值,這個值在測試環節就會固定下來。
[niceskyabc ] 在Tensorflow中實現leakyRelu操作詳解(高效)已經有382次圍觀
