前言
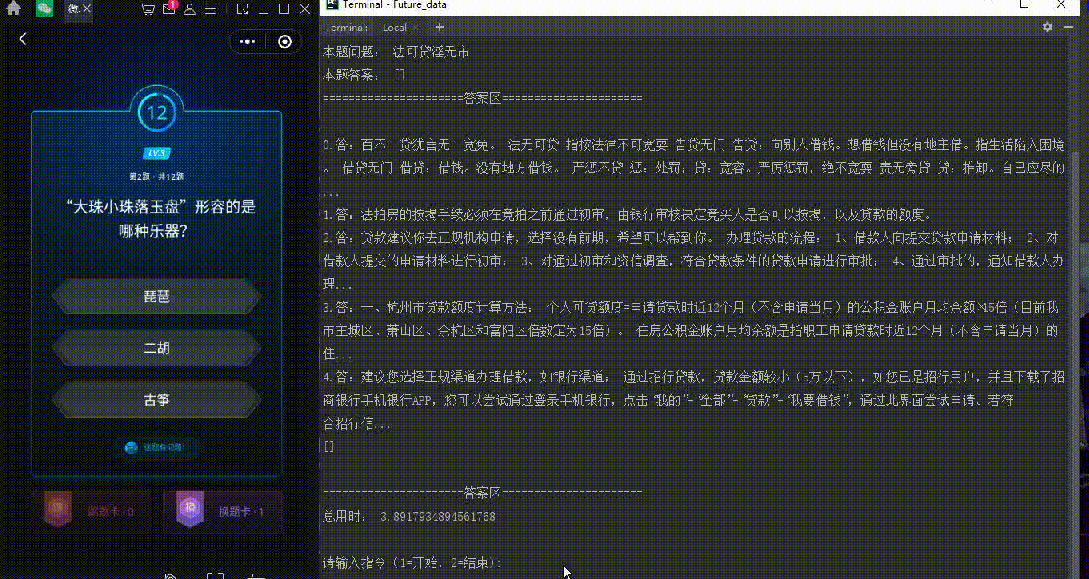
最近每天都有玩微信讀書上面的每日一答的答題遊戲,完全答對12題後,可以瓜分無限閱讀卡。但是從小就不太愛看書的我,很難連續答對12道題,由此,產生了寫一個半自動答題小程序的想法。我們先看一張效果圖吧(ps 這裡主要是我電腦有點卡,點擊左邊地選項有延遲)
項目GIthub地址: 微信讀書答題python小程序
覺得對你有幫助的請點個⭐來支持一下吧。
演示圖:
做前準備
mumu模擬器 因為手邊沒有安卓手機,所以只能在模擬器上進行模擬,如果手上有安卓手機地,可以適當地修改一下程序。需要安裝微信和微信讀書這兩個軟件
python工具包:BeautifulSoup4、Pillow、urllib、requests、re、base64、time
思路
截屏含有題目和答案的圖片(範圍可以自己指定)
使用百度的圖片識別技術將圖片轉化為文字,並進行一系列處理,分別將題目和答案進行存儲
調動百度知道搜索接口,將題目作為搜索關鍵字進行答案搜索
將搜索出來的內容使用BeautifulSoup4進行答案提取,這裡可以設置答案提取數量
將搜索結果進行輸出顯示
附:這裡我還加了一個自動推薦答案,利用百度短文本相似接口和選項是否出現在答案中這兩種驗證方法進行驗證,推薦相似度最高的答案。準確度還可以,但是比較耗時間,比正常情況下時間要多上一倍。
開始寫代碼
1. 導入工具包
import requests #訪問網站 import re #正則表達式匹配 import base64 #編碼 from bs4 import BeautifulSoup #處理頁面數據 from urllib import parse #進行url編碼 import time #統計時間 from PIL import ImageGrab #處理圖片
2. 編寫類和初始化方法
class autogetanswer(): def __init__(self,StartAutoRecomment=True,answernumber=5): self.StartAutoRecomment=StartAutoRecomment self.APIKEY=['BICrxxxxxxxxNNI','CrHGxxxxxxxx3C'] self.SECRETKEY=['BgL4jxxxxxxxxxGj9','1xo0jxxxxxx90cx'] self.accesstoken=[] self.baiduzhidao='http://zhidao.baidu.com/search?' self.question='' self.answer=[] self.answernumber=answernumber self.searchanswer=[] self.answerscore=[] self.reanswerindex=0 self.imageurl='answer.jpg' self.position=(35,155,355,680) self.titleregular1=r'(10題|共10|12題|共12|翻倍)' self.titleregular2=r'(?|?)' self.answerregular1=r'(這題|問題|跳題|換題|題卡|換卡|跳卡|這有)'
self.StartAutoRecomment 是否開啟自動推薦答案,默認為True
self.APIKEY 百度圖像轉文字、百度短文本相似度分析 這兩個接口的apikey
self.SECRETKEY 百度圖像轉文字、百度短文本相似度分析 這兩個接口的secretkey
這兩個key值我就沒法提供給大家了,大家可以自己去百度雲官方申請,免費額度大概有5萬,足夠我們使用了。
申請過程大家可以參考這個博客,很簡單的 如何申請百度文字識別apikey和Secret Key
self.accesstoken 存儲申請使用接口的accesstoken值
self.baiduzhidao 百度知道搜索接口地址
self.imageurl 圖片地址
self.position 截圖方位信息,依次分別是左間距、上間距、右間距、下間距
self.titleregular1、.titleregular2、answerregular1 這些是進行題目和答案處理的條件
3. 獲得accesstoken值
def GetAccseetoken(self): for i in range(len(self.APIKEY)): host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(self.APIKEY[i],self.SECRETKEY[i]) respOnse= requests.get(host) jsOndata= response.json() self.accesstoken.append(jsondata['access_token'])這是官方提供的獲取accesstoken的摸板,大家直接使用就行了。
4. 圖像轉文字以及相關處理
def OCR(self,filename): request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" # 二進制方式打開圖片文件 f = open(filename, 'rb') img = base64.b64encode(f.read()) params = {"image":img} access_token = self.accesstoken[0] request_url = request_url + "?access_token=" + access_token headers = {'content-type': 'application/x-www-form-urlencoded'} respOnse= requests.post(request_url, data=params, headers=headers) #===上面是使用百度圖片轉文字接口轉化,返回格式為json if response: result = response.json() questiOnstart=0 answerstart=0 self.question='' self.answer=[] #確定題目和答案所在的位置 for i in range(result['words_result_num']): if(re.search(self.titleregular1,result['words_result'][i]['words'])!=None): questiOnstart=i+1 if(re.search(self.titleregular2,result['words_result'][i]['words'])!=None): answerstart=i+1 #下面是進行題目和答案的處理 if(answerstart!=0): for title in result['words_result'][questionstart:answerstart]: if(re.search(self.answerregular1,title['words'])!=None): pass else: self.question+=title['words'] for answer in result['words_result'][answerstart:]: if(re.search(self.answerregular1,answer['words'])!=None): pass else: if(str(answer['words']).find('.')>0): answer2 = str(answer['words']).split('.')[-1] else: answer2=answer['words'] self.answer.append(answer2) else: for title in result['words_result'][questionstart:]: if(re.search(self.answerregular1,title['words'])!=None): pass else: self.question+=title['words'] print("本題問題:",self.question) print("本題答案:",self.answer) return response.json()#可有可無此方法是將圖片轉化為文字,進行圖片中的文字識別,格式如下:
{ "log_id": 2471272194, "words_result_num": 2, "words_result": [ {"words": " TSINGTAO"}, {"words": "青�u睥酒"} ] }下面我們以下面的圖為例,我們是如何去除掉干擾信息的:

上圖就是程序在實際運行中的情況,黃色框內就是程序截取的圖像(這個通過初始化方法的參數中的position可以進行設置),
我們需要的是紅色框內的信息,這包含題目和答案選項。文字識別後,白色框裡面的字也會和紅色框裡的字一同被識別,並以json形式輸出,這些信息對我們就是干擾信息,所以,我通過建立了初始化方法裡titleregular1、titleregular2、answerregular1 這三個標準進行判定,白色框裡的文字與對應,如果判斷包含的話,就不添加到題目中或者答案中。
5. 百度知道進行答案搜索
def BaiduAnswer(self): request = requests.session() headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'} data = {"word":self.question} url=self.baiduzhidao+'lm=0&rn=10&pn=0&fr=search&ie=gbk&'+parse.urlencode(data,encoding='GB2312') ress = request.get(url,headers=headers) ress.encoding='gbk' if ress: soup = BeautifulSoup(ress.text,'lxml') result = soup.find_all("dd",class_="dd answer") if(len(result)!=0 and len(result)>self.answernumber): length=5 else: length=len(result) for i in range(length): self.searchanswer.append(result[i].text)這裡是模擬瀏覽器進行百度知道搜索答案,將返回的文本交給BeautifulSoup進行處理,提取出我們需要的部分。後面最後幾句有一個判定,如果查詢到的答案數量超過我們設置的答案數,比如是5,那麼就將前5個答案放入searchanswer列表中,如果查詢到的答案數量要少於我們設置的,返回所有答案。
6. 短文本相似度分析
def CalculateSimilarity(self,text1,text2): access_token = self.accesstoken[1] request_url="https://aip.baidubce.com/rpc/2.0/nlp/v2/simnet" request_url = request_url + "?access_token=" + access_token headers = {'Content-Type': 'application/json'} data={"text_1":text1,"text_2":text2,"model":"GRNN"} respOnse= requests.post(request_url, json=data, headers=headers) response.encoding='gbk' if response: try: result = response.json() return result['score'] except: return 0這裡調用的是百度短文本相似度分析的接口,用於分析選項與查詢到的答案的相似度,以此來推薦一個參考答案。這個是官方給的摸板,直接調用,更換一下參數即可。
7. 自動給出一個參考答案
def AutoRecomment(self): if(len(self.answer)==0): return for i in range(len(self.answer)): scores=[] flag=0 for j in range(len(self.searchanswer)): if(j!=0and (j%2==0)): time.sleep(0.1) score = tools.CalculateSimilarity(tools.answer[i],tools.searchanswer[j]) if(tools.answer[i] in tools.searchanswer[j]): score=1 scores.append(score) if(score>0.8): flag=1 self.answerscore.append(score) break if(flag==0): self.answerscore.append(max(scores)) self.reanswerindex = self.answerscore.index(max(self.answerscore))
這裡調用了咱們第六步的CalculateSimilarity()方法,統計每一個選項與搜索到的答案相似度,取最高的存入answerscore列表中。這裡我又加了一個操作,我發現這個相似度匹配有時正確率比較低,所以這裡加了一個判定,若選項在搜索到的答案中出現,給予一個最大相似值,也就是1,這就大大提高了推薦的準確度。
8. 初始化參數
def IniParam(self): self.accesstoken=[] self.question='' self.answer=[] self.searchanswer=[] self.answerscore=[] self.reanswerindex=0
相關參數的初始化,因為每進行完一道題,要對存儲題和答案以及相關信息的數組進行清空,否則會對後面題的顯示產生影響。
9. 主方法
def MainMethod(self): while(True): try: order = input('請輸入指令(1=開始,2=結束):') if(int(order)==1): start = time.time() self.GetAccseetoken() img = ImageGrab.grab(self.position)#左、上、右、下 img.save(self.imageurl) self.OCR(self.imageurl) self.BaiduAnswer() if(self.StartAutoRecomment): self.AutoRecomment() print("======================答案區====================== ") for i in range(len(self.searchanswer)): print("{}.{}".format(i,self.searchanswer[i])) end = time.time() print(self.answerscore) if(self.StartAutoRecomment and len(self.answer)>0): print(" 推薦答案:",self.answer[self.reanswerindex]) print(" ======================答案區======================") print("總用時:",end-start,end=" ") self.IniParam() else: break except: print("識別失敗,請重新嘗試") self.IniParam() pass這裡主要是一個while循環,通過輸入指定來判斷是否結束循環。
這裡說一下下面這兩個語句:
img = ImageGrab.grab(self.position)#左、上、右、下 img.save(self.imageurl)
這兩個語句是用來截取我們指定位置的圖片,然後進行圖片的保存。
[hongdian2012 ] 從0到1使用python開發一個半自動答題小程序的實現已經有230次圍觀
