1、讀Hive表數據
pyspark讀取hive數據非常簡單,因為它有專門的接口來讀取,完全不需要像hbase那樣,需要做很多配置,pyspark提供的操作hive的接口,使得程序可以直接使用SQL語句從hive裡面查詢需要的數據,代碼如下:
from pyspark.sql import HiveContext,SparkSession _SPARK_HOST = "spark://spark-master:7077" _APP_NAME = "test" spark_session = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate() hive_context= HiveContext(spark_session ) # 生成查詢的SQL語句,這個跟hive的查詢語句一樣,所以也可以加where等條件語句 hive_database = "database1" hive_table = "test" hive_read = "select * from {}.{}".format(hive_database, hive_table) # 通過SQL語句在hive中查詢的數據直接是dataframe的形式 read_df = hive_context.sql(hive_read)
2 、將數據寫入hive表
pyspark寫hive表有兩種方式:
(1)通過SQL語句生成表
from pyspark.sql import SparkSession, HiveContext _SPARK_HOST = "spark://spark-master:7077" _APP_NAME = "test" spark = SparkSession.builder.master(_SPARK_HOST).appName(_APP_NAME).getOrCreate() data = [ (1,"3","145"), (1,"4","146"), (1,"5","25"), (1,"6","26"), (2,"32","32"), (2,"8","134"), (2,"8","134"), (2,"9","137") ] df = spark.createDataFrame(data, ['id', "test_id", 'camera_id']) # method one,default是默認數據庫的名字,write_test 是要寫到default中數據表的名字 df.registerTempTable('test_hive') sqlContext.sql("create table default.write_test select * from test_hive")
(2)saveastable的方式
# method two # "overwrite"是重寫表的模式,如果表存在,就覆蓋掉原始數據,如果不存在就重新生成一張表 # mode("append")是在原有表的基礎上進行添加數據 df.write.format("hive").mode("overwrite").saveAsTable('default.write_test')
tips:
spark用上面幾種方式讀寫hive時,需要在提交任務時加上相應的配置,不然會報錯:
spark-submit --conf spark.sql.catalogImplementation=hive test.py
補充知識:PySpark基於SHC框架讀取HBase數據並轉成DataFrame
一、首先需要將HBase目錄lib下的jar包以及SHC的jar包複製到所有節點的Spark目錄lib下
二、修改spark-defaults.conf 在spark.driver.extraClassPath和spark.executor.extraClassPath把上述jar包所在路徑加進去
三、重啟集群
四、代碼
#/usr/bin/python #-*- coding:utf-8 �C*- from pyspark import SparkContext from pyspark.sql import SQLContext,HiveContext,SparkSession from pyspark.sql.types import Row,StringType,StructField,StringType,IntegerType from pyspark.sql.dataframe import DataFrame sc = SparkContext(appName="pyspark_hbase") sql_sc = SQLContext(sc) dep = "org.apache.spark.sql.execution.datasources.hbase" #定義schema catalog = """{ "table":{"namespace":"default", "name":"teacher"}, "rowkey":"key", "columns":{ "id":{"cf":"rowkey", "col":"key", "type":"string"}, "name":{"cf":"teacherInfo", "col":"name", "type":"string"}, "age":{"cf":"teacherInfo", "col":"age", "type":"string"}, "gender":{"cf":"teacherInfo", "col":"gender","type":"string"}, "cat":{"cf":"teacherInfo", "col":"cat","type":"string"}, "tag":{"cf":"teacherInfo", "col":"tag", "type":"string"}, "level":{"cf":"teacherInfo", "col":"level","type":"string"} } }""" df = sql_sc.read.options(catalog = catalog).format(dep).load() print ('***************************************************************') print ('***************************************************************') print ('***************************************************************') df.show() print ('***************************************************************') print ('***************************************************************') print ('***************************************************************') sc.stop()
五、解釋
數據來源參考請本人之前的文章,在此不做贅述
schema定義參考如圖:
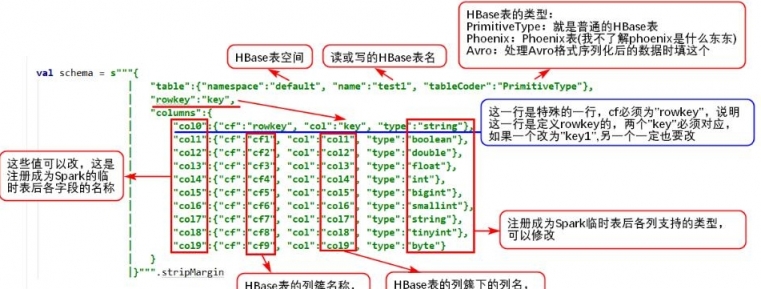
六、結果
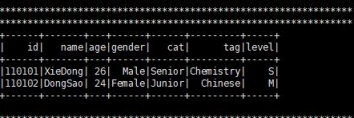
[ljg58026 ] 在python中使用pyspark讀寫Hive數據操作已經有356次圍觀
