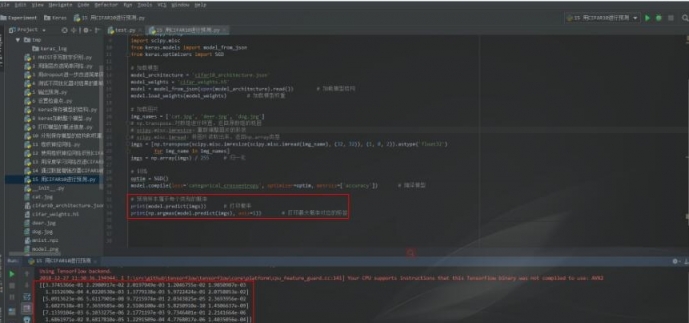
1 predict()方法
當使用predict()方法進行預測時,返回值是數值,表示樣本屬於每一個類別的概率,我們可以使用numpy.argmax()方法找到樣本以最大概率所屬的類別作為樣本的預測標籤。
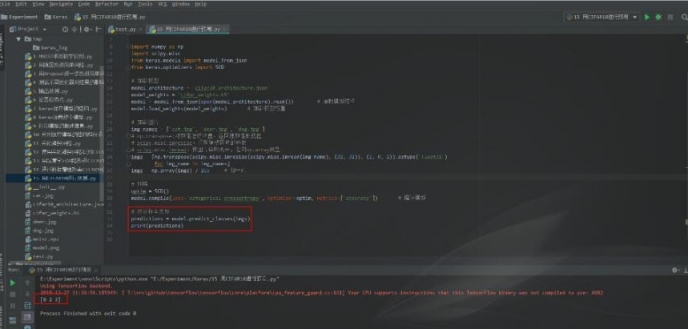
2 predict_classes()方法
當使用predict_classes()方法進行預測時,返回的是類別的索引,即該樣本所屬的類別標籤。以卷積神經網絡中的圖片分類為例說明,代碼如下:
補充知識:keras中model.evaluate、model.predict和model.predict_classes的區別
1、model.evaluate 用於評估您訓練的模型。它的輸出是model的acc和loss,而不是對輸入數據的預測。
2、model.predict 實際預測,輸入為test sample,輸出為label。
3、在keras中有兩個預測函數model.predict_classes(test) 和model.predict(test)。如果標籤經過了one-hot編碼,如[1,2,3,4,5]是標籤類別,經編碼後為[1 0 0 0 0],[0 1 0 0 0]…[0 0 0 0 1]。
model.predict_classes(test)預測的是類別,打印出來的值就是類別號。並且只能用於序列模型來預測,不能用於函數式模型。
而model.predict(test)輸出的還是5個編碼值,要經過argmax(predict_test,axis=1)轉化為類別號。
[lousu-xi ] 對Keras中predict()方法和predict已經有1982次圍觀
