如有錯誤,歡迎斧正。
我的答案是,在Conv2D輸入通道為1的情況下,二者是沒有區別或者說是可以相互轉化的。首先,二者調用的最後的代碼都是後端代碼(以TensorFlow為例,在tensorflow_backend.py裡面可以找到):
x = tf.nn.convolution( input=x, filter=kernel, dilation_rate=(dilation_rate,), strides=(strides,), padding=padding, data_format=tf_data_format)
區別在於input和filter傳遞的參數不同,input不必說,filter=kernel是什麼呢?
我們進入Conv1D和Conv2D的源代碼看一下。他們的代碼位於layers/convolutional.py裡面,二者繼承的都是基類_Conv(Layer)。
進入_Conv類查看代碼可以發覺以下代碼:
self.kernel_size = conv_utils.normalize_tuple(kernel_size, rank, 'kernel_size') ……#中間代碼省略 input_dim = input_shape[channel_axis] kernel_shape = self.kernel_size + (input_dim, self.filters)
我們假設,Conv1D的input的大小是(600,300),而Conv2D的input大小是(m,n,1),二者kernel_size為3。
進入conv_utils.normalize_tuple函數可以看到:
def normalize_tuple(value, n, name): """Transforms a single int or iterable of ints into an int tuple. # Arguments value: The value to validate and convert. Could an int, or any iterable of ints. n: The size of the tuple to be returned. name: The name of the argument being validated, e.g. "strides" or "kernel_size". This is only used to format error messages. # Returns A tuple of n integers. # Raises ValueError: If something else than an int/long or iterable thereof was passed. """ if isinstance(value, int): return (value,) * n else: try: value_tuple = tuple(value) except TypeError: raise ValueError('The `' + name + '` argument must be a tuple of ' + str(n) + ' integers. Received: ' + str(value)) if len(value_tuple) != n: raise ValueError('The `' + name + '` argument must be a tuple of ' + str(n) + ' integers. Received: ' + str(value)) for single_value in value_tuple: try: int(single_value) except ValueError: raise ValueError('The `' + name + '` argument must be a tuple of ' + str(n) + ' integers. Received: ' + str(value) + ' ' 'including element ' + str(single_value) + ' of type' + ' ' + str(type(single_value))) return value_tuple
所以上述代碼得到的kernel_size是kernel的實際大小,根據rank進行計算,Conv1D的rank為1,Conv2D的rank為2,如果是Conv1D,那麼得到的kernel_size就是(3,)如果是Conv2D,那麼得到的是(3,3)
input_dim = input_shape[channel_axis] kernel_shape = self.kernel_size + (input_dim, self.filters)
又因為以上的inputdim是最後一維大小(Conv1D中為300,Conv2D中為1),filter數目我們假設二者都是64個卷積核。
因此,Conv1D的kernel的shape實際為:
(3,300,64)
而Conv2D的kernel的shape實際為:
(3,3,1,64)
剛才我們假設的是傳參的時候kernel_size=3,如果,我們將傳參Conv2D時使用的的kernel_size設置為自己的元組例如(3,300),那麼傳根據conv_utils.normalize_tuple函數,最後的kernel_size會返回我們自己設置的元組,也即(3,300)那麼Conv2D的實際shape是:
(3,300,1,64),也即這個時候的Conv1D的大小reshape一下得到,二者等價。
換句話說,Conv1D(kernel_size=3)實際就是Conv2D(kernel_size=(3,300)),當然必須把輸入也reshape成(600,300,1),即可在多行上進行Conv2D卷積。
這也可以解釋,為什麼在Keras中使用Conv1D可以進行自然語言處理,因為在自然語言處理中,我們假設一個序列是600個單詞,每個單詞的詞向量是300維,那麼一個序列輸入到網絡中就是(600,300),當我使用Conv1D進行卷積的時候,實際上就完成了直接在序列上的卷積,卷積的時候實際是以(3,300)進行卷積,又因為每一行都是一個詞向量,因此使用Conv1D(kernel_size=3)也就相當於使用神經網絡進行了n_gram=3的特徵提取了。
這也是為什麼使用卷積神經網絡處理文本會非常快速有效的內涵。
補充知識:Conv1D、Conv2D、Conv3D
由於計算機視覺的大紅大紫,二維卷積的用處範圍最廣。因此本文首先介紹二維卷積,之後再介紹一維卷積與三維卷積的具體流程,並描述其各自的具體應用。
1. 二維卷積
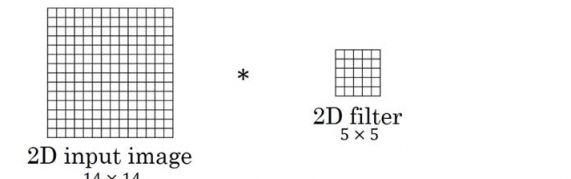
圖中的輸入的數據維度為
上述內容沒有引入channel的概念,也可以說channel的數量為1。如果將二維卷積中輸入的channel的數量變為3,即輸入的數據維度變為(
以上都是在過濾器數量為1的情況下所進行的討論。如果將過濾器的數量增加至16,即16個大小為
二維卷積常用於計算機視覺、圖像處理領域。
2. 一維卷積
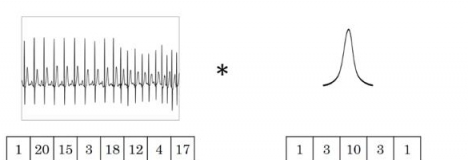
圖中的輸入的數據維度為8,過濾器的維度為5。與二維卷積類似,卷積後輸出的數據維度為
如果過濾器數量仍為1,輸入數據的channel數量變為16,即輸入數據維度為
如果過濾器數量為
一維卷積常用於序列模型,自然語言處理領域。
3. 三維卷積
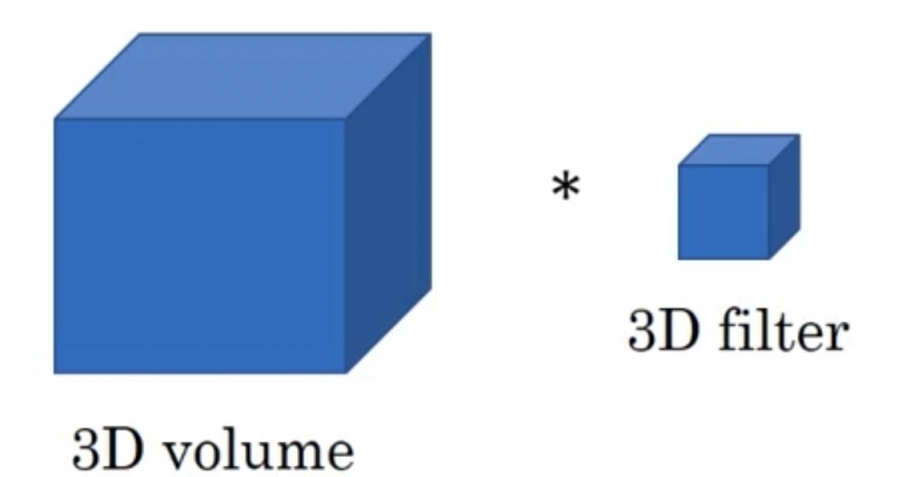
這裡採用代數的方式對三維卷積進行介紹,具體思想與一維卷積、二維卷積相同。
假設輸入數據的大小為
基於上述情況,三維卷積最終的輸出為
三維卷積常用於醫學領域(CT影響),視頻處理領域(檢測動作及人物行為)。
[limiyoyo ] 基於Keras中Conv1D和Conv2D的區別說明已經有360次圍觀
