本文系網上搜集和整理參考http://hi.baidu.com/coolhayy/blog/item/7a311da2750f5ca7caefd0e9.html
查看linux的cpu信息 cat /proc/cpuinfo
查看linux的cpu數目 grep 'module name' /proc/cpuinfo |wc -l
以單個cpu來計算如果負載為1.00表示系統資源正好用完,多一個核心滿負載值 1
查看linux系統負載1.top 2.w 3.uptime 4.cat /proc/loadavg
命令的輸出結果表示一段時間內運行隊列中的平均進程數量.一般來說只要每個CPU的當
前活動進程數不大於3那麼系統的性能就是良好的,如果每個CPU的任務數大於5,那麼就
表示這台機器的性能有嚴重問題.
cat /proc/loadavg”命令,輸出結果如下:
0.27 0.36 0.37 4/83 4828/
前三個數字大家都知道,是1、5、15分鐘內的平均進程數(有人認為是系統負荷的百分比
,其實不然,有些時候可以看到200甚至更多).後面兩個呢,一個的分子是正在運行的
進程數,分母是進程總數;另一個是最近運行的進程ID號.
vmstat查看系統負載
Vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 100152 2436 97200 289740 0 1 34 45 99 33 0 0 99 0
procs
r 列表示運行和等待cpu時間片的進程數,如果長期大於1,說明cpu不足,需要增加cpu.
b 列表示在等待資源的進程數,比如正在等待I/O、或者內存交換等.
cpu 表示cpu的使用狀態
us 列顯示了用戶方式下所花費 CPU 時間的百分比.us的值比較高時,說明用戶進程消耗
的cpu時間多,但是如果長期大於50%,需要考慮優化用戶的程序.
sy 列顯示了內核進程所花費的cpu時間的百分比.這裡us sy的參考值為80%,如果
us sy 大於 80%說明可能存在CPU不足.
wa 列顯示了IO等待所佔用的CPU時間的百分比.這裡wa的參考值為30%,如果wa超過30%,
說明IO等待嚴重,這可能是磁碟大量隨機訪問造成的,也可能磁碟或者磁碟訪問控制器的
帶寬瓶頸造成的(主要是塊操作).
id 列顯示了cpu處在空閑狀態的時間百分比
system 顯示採集間隔內發生的中斷數
in 列表示在某一時間間隔中觀測到的每秒設備中斷數.
cs列表示每秒產生的上下文切換次數,如當 cs 比磁碟 I/O 和網路信息包速率高得多,
都應進行進一步調查.
memory
swpd 切換到內存交換區的內存數量(k表示).如果swpd的值不為0,或者比較大,比如超
過了100m,只要si、so的值長期為0,系統性能還是正常
free 當前的空閑頁面列表中內存數量(k表示)
buff 作為buffer cache的內存數量,一般對塊設備的讀寫才需要緩衝.
cache: 作為page cache的內存數量,一般作為文件系統的cache,如果cache較大,說明
用到cache的文件較多,如果此時IO中bi比較小,說明文件系統效率比較好.
swap
si 由內存進入內存交換區數量.
so由內存交換區進入內存數量.
IO
bi 從塊設備讀入數據的總量(讀磁碟)(每秒kb).
bo 塊設備寫入數據的總量(寫磁碟)(每秒kb)
這裡我們設置的bi bo參考值為1000,如果超過1000,而且wa值較大應該考慮均衡磁碟負
載,可以結合iostat輸出來分析
查看磁碟負載iostat
每隔2秒統計一次磁碟IO信息,直到按Ctrl C終止程序,-d 選項表示統計磁碟信息, -k
表示以每秒KB的形式顯示,-t 要求列印出時間信息,2 表示每隔 2 秒輸出一次.第一次
輸出的磁碟IO負載狀況提供了關於自從系統啟動以來的統計信息.隨後的每一次輸出則是每個間隔之間的平均IO負載狀況.
# iostat -x 1 10
Linux 2.6.18-92.el5xen 02/03/2009
avg-cpu: %user %nice %system %iowait %steal %idle
1.10 0.00 4.82 39.54 0.07 54.46
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 3.50 0.40 2.50 5.60 48.00 18.48 0.00 0.97 0.97 0.28
sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.10 0.30 0.20 2.40 2.40 9.60 0.00 1.60 1.60 0.08
sdf 17.40 0.50 102.00 0.20 12095.20 5.60 118.40 0.70 6.81 2.09 21.36
sdg 232.40 1.90 379.70 0.50 76451.20 19.20 201.13 4.94 13.78 2.45 93.16
rrqm/s: 每秒進行 merge 的讀操作數目.即 delta(rmerge)/s
wrqm/s: 每秒進行 merge 的寫操作數目.即 delta(wmerge)/s
r/s: 每秒完成的讀 I/O 設備次數.即 delta(rio)/s
w/s: 每秒完成的寫 I/O 設備次數.即 delta(wio)/s
rsec/s: 每秒讀扇區數.即 delta(rsect)/s
wsec/s: 每秒寫扇區數.即 delta(wsect)/s
rkB/s: 每秒讀K位元組數.是 rsect/s 的一半,
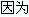
每扇區大小為512位元組.(需要計算)
wkB/s: 每秒寫K位元組數.是 wsect/s 的一半.(需要計算)
avgrq-sz: 平均每次設備I/O操作的數據大小 (扇區).delta(rsect wsect)/delta(rio wio)
avgqu-sz: 平均I/O隊列長度.即 delta(aveq)/s/1000 (
aveq的單位為毫秒).
await: 平均每次設備I/O操作的等待時間 (毫秒).即 delta(ruse wuse)/delta(rio wio)
svctm: 平均每次設備I/O操作的服務時間 (毫秒).即 delta(use)/delta(rio wio)
%util: 一秒中有百分之多少的時間用於 I/O 操作,或者說一秒中有多少時間 I/O 隊列是非空的.即 delta(use)/s/1000 (
use的單位為毫秒)
如果 %util 接近 100%,說明產生的I/O請求太多,I/O系統已經滿負荷,該磁碟
可能存在瓶頸.
idle小於70% IO壓力就較大了,一般讀取速度有較多的wait.
同時可以結合vmstat 查看查看b參數(等待資源的進程數)和wa參數(IO等待所佔用的CPU時間的百分比,高過30%時IO壓力高)
另外還可以參考
一般:
svctm < await (
同時等待的請求的等待時間被重複計算了),
svctm的大小一般和磁碟性能有關:CPU/內存的負荷也會對其有影響,請求過多也會間接導致 svctm 的增加.
await: await的大小一般取決於服務時間(svctm) 以及 I/O 隊列的長度和 I/O 請求的發出模式.
如果 svctm 比較接近 await,說明I/O 幾乎沒有等待時間;
如果 await 遠大於 svctm,說明 I/O隊列太長,應用得到的響應時間變慢,
如果響應時間超過了用戶可以容許的範圍,這時可以考慮更換更快的磁碟,調整內核 elevator演算法,優化應用,或者升級 CPU.
隊列長度(avgqu-sz)也可作為衡量系統 I/O 負荷的指標,但由於 avgqu-sz 是按照單
位時間的平均值,
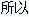
不能反映瞬間的 I/O 洪水.
別人一個不錯的例子.(I/O 系統 vs. 超市排隊)
舉一個例子,我們在超市排隊 checkout 時,怎麼決定該去哪個交款台呢? 首當是看
排的隊人數,5個人總比20人要快吧?除了數人頭,我們也常常看看前面人購買的東西多少
,如果前面有個採購了一星期食品的大媽,那麼可以考慮換個隊排了.還有就是收銀員的
速度了,如果碰上了連錢都點不清楚的新手,那就有的等了.另外,時機也很重要,可能
5分鐘前還人滿為患的收款台,現在已是人去樓空,這時候交款可是很爽啊,當然,前提
是那過去的 5 分鐘里所做的事情比排隊要有意義(不過我還沒發現什麼事情比排隊還無聊
的).
I/O 系統也和超市排隊有很多類似之處:
r/s w/s 類似於交款人的總數
平均隊列長度(avgqu-sz)類似於單位時間裡平均排隊人的個數
平均服務時間(svctm)類似於收銀員的收款速度
平均等待時間(await)類似於平均每人的等待時間
平均I/O數據(avgrq-sz)類似於平均每人所買的東西多少
I/O 操作率 (%util)類似於收款台前有人排隊的時間比例.
我們可以根據這些數據分析出 I/O 請求的模式,以及 I/O 的速度和響應時間.
下面是別人寫的這個參數輸出的分析
# iostat -x 1
avg-cpu: %user %nice %sys %idle
16.24 0.00 4.31 79.44
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
/dev/cciss/c0d0
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p1
0.00 44.90 1.02 27.55 8.16 579.59 4.08 289.80 20.57 22.35 78.21 5.00 14.29
/dev/cciss/c0d0p2
0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
上面的 iostat 輸出表明秒有 28.57 次設備 I/O 操作: 總IO(io)/s = r/s(讀)
w/s(寫) = 1.02 27.55 = 28.57 (次/秒) 其中寫操作佔了主體 (w:r = 27:1).
平均每次設備 I/O 操作只需要 5ms 就可以完成,但每個 I/O 請求卻需要等上 78ms
,為什麼?
發出的 I/O 請求太多 (每秒鐘約 29 個),假設這些請求是同時發出的,
那麼平均等待時間可以這樣計算:
平均等待時間 = 單個 I/O 服務時間 * ( 1 2 ... 請求總數-1) / 請求總數
應用到上面的例子: 平均等待時間 = 5ms * (1 2 ... 28)/29 = 70ms,和 iostat 給
出的78ms 的平均等待時間很接近.這反過來表明 I/O 是同時發起的.
每秒發出的 I/O 請求很多 (約 29 個),平均隊列卻不長 (只有 2 個 左右),這表明
這 29 個請求的到來並不均勻,大部分時間 I/O 是空閑的.
一秒中有 14.29% 的時間 I/O 隊列中是有請求的,也就是說,85.71% 的時間裡 I/O
系統無事可做,所有 29 個 I/O 請求都在142毫秒之內處理掉了.
delta(ruse wuse)/delta(io) = await = 78.21 => delta(ruse wuse)/s=78.21 *
delta(io)/s = 78.21*28.57 =2232.8,表明每秒內的I/O請求總共需要等待2232.8ms.所
以平均隊列長度應為 2232.8ms/1000ms = 2.23,而iostat 給出的平均隊列長度 (avgqu
-sz) 卻為 22.35,為什麼?!
iostat 中有 bug,avgqu-sz值應為 2.23,而不是
22.35.
本文出自 「成長全記錄」 博客,請務必保留此出處http://lymrg.blog.51cto.com/1551327/426627
