最近在做應用的性能優化,在review代碼的過程中積累了一些規則和經驗.做到這些規則的目的很簡單,就是寫出"優美"的代碼來.
1、註釋儘可能全面
對於方法的註釋應該包含詳細的入參和結果說明,有異常拋出的情況也要詳細敘述;類的註釋應該包含類的功能說明、作者和修改者.
2、多次使用的相同變數最好歸納成常量
多處使用的相同值的變數應該盡量歸納為一個常量,方便日後的維護.
3、盡量少的在循環中執行方法調用
盡量在循環中少做一些可避免的方法調用,這樣可以節省方法棧的創建.例如:
for(int i=0;i<list.size();i ){
System.out.println(i);
}
可以修改為:
for(int i=0,size=list.size();i<size;i ){
System.out.println(i);
}
4、常量的定義可以放到介面中
在Java中,介面里只允許存在常量,因此把常量放到介面中聲明就可以省去public static final這幾個關鍵詞.
5、ArrayList和LinkedList的選擇
這個問題比較常見.通常程序員最好能夠對list的使用場景做出評估,然後根據特性作出選擇.ArrayList底層是使用數組實現的,因此隨機讀取數據會比LinkedList快很多,而LinkedList是使用鏈表實現的,新增和刪除數據的速度比ArrayList快不少.
6、String,StringBuffer和StringBuilder
這個問題也比較常見.在進行字元串拼接處理的時候,String通常會產生多個對象,而且將多個值緩存到常量池中.例如:
String a="a";
String b="b";
a=a b;
這種情況下jvm會產生"a","b","ab"三個對象.而且字元串拼接的性能也很低.因此通常需要做字元串處理的時候盡量採用StringBuffer和StringBuilder來.
7、包裝類和基本類型的選擇
在代碼中,如果可以使用基本數據類型來做局部變數類型的話盡量使用基本數據類型,
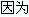
基本類型的變數是存放在棧中的,包裝類的變數是在堆中,棧的操作速度比堆快很多.
8、儘早的將不再使用的變數引用賦給null
這樣做可以幫助jvm更快的進行內存回收.當然很多人其實對這種做法並不感冒.
9、在finally塊中對資源進行釋放
典型的場景是使用io流的時候,不論是否出現異常

都應該在finally中對流進行關閉.
10、在HashMap中使用一個Object作為key時要注意如何區分Object是否相同
在jdk的HashMap實現中,判斷兩個Object類型的key是否相同的標準是hashcode是否相同和equals方法的返回值.如果業務上需要對兩個數據相同的內存對象當作不同的key存儲到hashmap中就要對hashcode和equals方法進行覆蓋.
