要說2017年什麼技術最火爆,無疑是google領銜的深度學習開源框架Tensorflow。本文簡述一下深度學習的入門例子MNIST。
深度學習簡單介紹
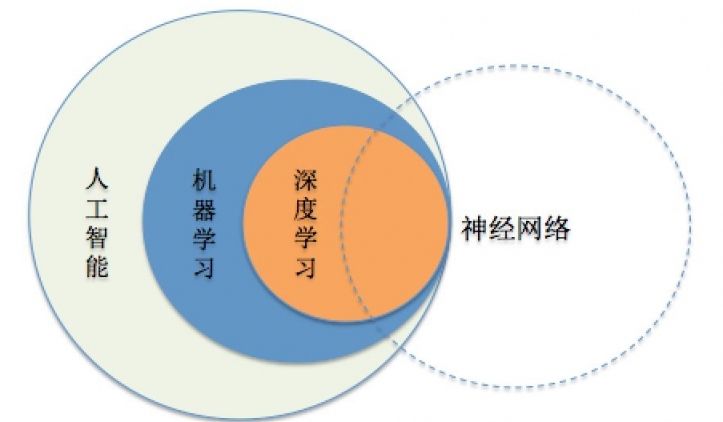
首先要簡單區別幾個概念:人工智能,機器學習,深度學習,神經網絡。這幾個詞應該是出現的最為頻繁的,但是他們有什麼區別呢?
人工智能:人類通過直覺可以解決的問題,如:自然語言理解,圖像識別,語音識別等,計算機很難解決,而人工智能就是要解決這類問題。
機器學習:如果一個任務可以在任務T上,隨著經驗E的增加,效果P也隨之增加,那麼就認為這個程序可以從經驗中學習。
深度學習:其核心就是自動將簡單的特徵組合成更加複雜的特徵,並用這些特徵解決問題。
神經網絡:最初是一個生物學的概念,一般是指大腦神經元,觸點,細胞等組成的網絡,用於產生意識,幫助生物思考和行動,後來人工智能受神經網絡的啟發,發展出了人工神經網絡。
來一張圖就比較清楚了,如下圖:
MNIST解析
MNIST是深度學習的經典入門demo,他是由6萬張訓練圖片和1萬張測試圖片構成的,每張圖片都是28*28大小(如下圖),而且都是黑白色構成(這裡的黑色是一個0-1的浮點數,黑色越深表示數值越靠近1),這些圖片是採集的不同的人手寫從0到9的數字。TensorFlow將這個數據集和相關操作封裝到了庫中,下面我們來一步步解讀深度學習MNIST的過程。

上圖就是4張MNIST圖片。這些圖片並不是傳統意義上.jpg或者jpg格式的圖片,因.jpg或者jpg的圖片格式,會帶有很多幹擾信息(如:數據塊,圖片頭,圖片尾,長度等等),這些圖片會被處理成很簡易的二維數組,如圖:
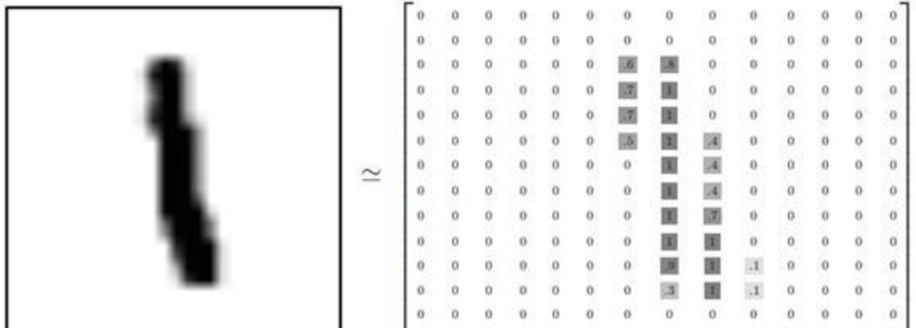
可以看到,矩陣中有值的地方構成的圖形,跟左邊的圖形很相似。之所以這樣做,是為了讓模型更簡單清晰。特徵更明顯。
我們先看模型的代碼以及如何訓練模型:
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) # x是特徵值 x = tf.placeholder(tf.float32, [None, 784]) # w表示每一個特徵值(像素點)會影響結果的權重 W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.matmul(x, W) + b # 是圖片實際對應的值 y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.InteractiveSession() tf.global_variables_initializer().run() # mnist.train 訓練數據 for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) #取得y得最大概率對應的數組索引來和y_的數組索引對比,如果索引相同,則表示預測正確 correct_prediction = tf.equal(tf.arg_max(y, 1), tf.arg_max(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
首先第一行是獲取MNIST的數據集,我們逐一解釋一下:
x(圖片的特徵值):這裡使用了一個28*28=784列的數據來表示一個圖片的構成,也就是說,每一個點都是這個圖片的一個特徵,這個其實比較好理解,因為每一個點都會對圖片的樣子和表達的含義有影響,只是影響的大小不同而已。至於為什麼要將28*28的矩陣攤平成為一個1行784列的一維數組,我猜測可能是因為這樣做會更加簡單直觀。
W(特徵值對應的權重):這個值很重要,因為我們深度學習的過程,就是發現特徵,經過一系列訓練,從而得出每一個特徵對結果影響的權重,我們訓練,就是為了得到這個最佳權重值。
b(偏置量):是為了去線性話(我不是太清楚為什麼需要這個值)
y(預測的結果):單個樣本被預測出來是哪個數字的概率,比如:有可能結果是[ 1.07476616 -4.54194021 2.98073649 -7.42985344 3.29253793 1.967506178.59438515 -6.65950203 1.68721473 -0.9658531 ],則分別表示是0,1,2,3,4,5,6,7,8,9的概率,然後會取一個最大值來作為本次預測的結果,對於這個數組來說,結果是6(8.59438515)
y_(真實結果):來自MNIST的訓練集,每一個圖片所對應的真實值,如果是6,則表示為:[0 0 0 0 0 1 0 0 0]
再下面兩行代碼是損失函數(交叉熵)和梯度下降算法,通過不斷的調整權重和偏置量的值,來逐步減小根據計算的預測結果和提供的真實結果之間的差異,以達到訓練模型的目的。
算法確定以後便可以開始訓練模型了,如下:
for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
mnist.train.next_batch(100)是從訓練集裡一次提取100張圖片數據來訓練,然後循環1000次,以達到訓練的目的。
之後的兩行代碼都有註釋,不再累述。我們看最後一行代碼:
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
mnist.test.images和mnist.test.labels是測試集,用來測試。accuracy是預測準確率。
當代碼運行起來以後,我們發現,準確率大概在92%左右浮動。這個時候我們可能想看看到底是什麼樣的圖片讓預測不準。則添加如下代碼:
for i in range(0, len(mnist.test.images)): result = sess.run(correct_prediction, feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])}) if not result: print('預測的值是:',sess.run(y, feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])})) print('實際的值是:',sess.run(y_,feed_dict={x: np.array([mnist.test.images[i]]), y_: np.array([mnist.test.labels[i]])})) one_pic_arr = np.reshape(mnist.test.images[i], (28, 28)) pic_matrix = np.matrix(one_pic_arr, dtype="float") plt.imshow(pic_matrix) pylab.show() break print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
for循環內指明一旦result為false,就表示出現了預測值和實際值不符合的圖片,然後我們把值和圖片分別打印出來看看:
預測的值是: [[ 1.82234347 -4.87242508 2.63052988 -6.56350136 2.73666072 2.30682945 8.59051228 -7.20512581 1.45552373 -0.90134078]]
對應的是數字6。
實際的值是: [[ 0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]]
對應的是數字5。
我們再來看看圖片是什麼樣子的:

的確像5又像6。
總體來說,只有92%的準確率,還是比較低的,後續會解析一下比較適合識別圖片的卷積神經網絡,準確率可以達到99%以上。
一些體會與感想
我本人是一名iOS開發,也是迎著人工智能的浪潮開始一路學習,我覺得人工智能終將改變我們的生活,也會成為未來的一個熱門學科。這一個多月的自學下來,我覺得最為困難的是克服自己的畏難情緒,因為我完全沒有AI方面的任何經驗,而且工作年限太久,線性代數,概率論等知識早已還給老師,所以在開始的時候,總是反反覆覆不停猶豫,糾結到底要不要把時間花費在研究深度學習上面。但是後來一想,假如我不學AI的東西,若干年後,AI發展越發成熟,到時候想學也會難以跟上步伐,而且,讓電腦學會思考這本身就是一件很讓人興奮的事情,既然想學,有什麼理由不去學呢?與大家共勉。
參考文章:
https://zhuanlan.zhihu.com/p/25482889
https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/chap1/c1s0.html
[月球人 ] 解析Tensorflow之MNIST的使用已經有248次圍觀
