在《遇見C++ PPL:C++的并行和非同步》里,我們介紹了如何使用C++ PPL在CPU上做并行計算,這次,我們會把舞台換成GPU,介紹如何使用C++ AMP在上面做并行計算。
接下來,我們將會在《遇見C++ PPL:C++的并行和非同步》的基礎上,對并行計算正弦值的代碼進行一番改造,使之可以在GPU上運行。如果你沒讀過那篇文章,我建議你先去讀一讀它的第一節。此外,本文也假設你對C++ Lambda有所了解,否則,我建議你先去讀一讀《遇見C++ Lambda》。
首先,包含/引用相關的頭文件/命名空間,如代碼1所示。amp.h是C++ AMP的頭文件,包含了相關的函數和類,它們位於concurrency命名空間之內。amp_math.h包含了常用的數學函數,如sin函數,concurrency::fast_math命名空間里的函數只支持單精度浮點數,而concurrency::precise_math命名空間里的函數則對單精度浮點數和雙精度浮點數均提供支持。
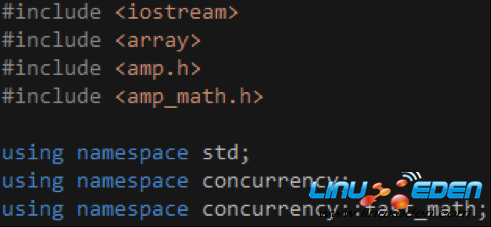
代碼 1
把浮點數的類型從double改成float,如代碼2所示,這樣做是因為並非所有GPU都支持雙精度浮點數的運算。另外,std和concurrency兩個命名空間都有一個array類,為了消除歧義,我們需要在array前面加上“std::”前綴,以便告知編譯器我們使用的是STL的array類。
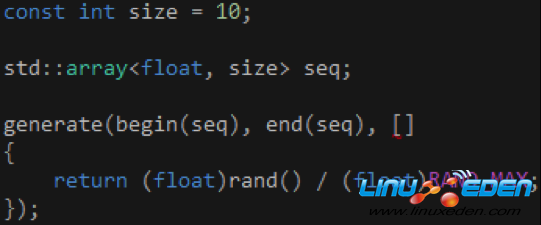
代碼 2
接著,創建一個array_view對象,把前面創建的array對象包裝起來,如代碼3所示。array_view對象只是一個包裝器,本身不能包含任何數據,必須和真正的容器搭配使用,如C風格的數組、STL的array對象或vector對象。當我們創建array_view對象時,需要通過類型參數指定array_view對象里的元素的類型以及它的維度,並通過構造函數的參數指定對應維度的長度以及包含實際數據的容器。

代碼 3
代碼3創建了一個一維的array_view對象,這個維度的長度和前面的array對象的長度一樣,這個包裝看起來有點多餘,為什麼要這樣做?這是因為在GPU上運行的代碼無法直接訪問系統內存里的數據,需要array_view對象出來充當一個橋樑的角色,使得在GPU上運行的代碼可以通過它間接訪問系統內存里的數據。事實上,在GPU上運行的代碼訪問的並非系統內存里的數據,而是複製到顯存的副本,而負責把這些數據從系統內存複製到顯存的正是array_view對象,這個過程是自動的,無需我們干預。
有了前面這些準備,我們就可以著手編寫在GPU上運行的代碼了,如代碼4所示。parallel_for_each函數可以看作C++ AMP的入口點,我們通過extent對象告訴它創建多少個GPU線程,通過Lambda告訴它這些GPU線程運行什麼代碼,我們通常把這個代碼稱作Kernel。

代碼 4
我們希望每個GPU線程可以完成和結果集里的某個元素對應的一組操作,比如說,我們需要計算10個浮點數的正弦值,那麼,我們希望創建10個GPU線程,每個線程依次完成讀取浮點數、計算正弦值和保存正弦值三個操作。但是,每個GPU線程運行的代碼都是一樣的,如何區分不同的GPU線程,並定位需要處理的數據呢?
這個時候就輪到index對象出場了,我們的array_view對象是一維的,因此index對象的類型是index<1>,這個維度的長度是10,因此將會產生從0到9的10個index對象,每個GPU線程對應其中一個index對象。這個index對象將會通過Lambda的參數傳給我們,而我們將會在Kernel里通過這個index對象找到當前GPU線程需要處理的數據。
既然Lambda的參數只傳遞index對象,那Kernel又是如何與外界交換數據的呢?我們可以通過閉包捕獲當前上下文的變數,這使我們可以靈活地操作多個數據源和結果集,因此沒有必要提供返回值。從這個角度來看,C++ AMP的parallel_for_each函數在用法上類似於C++ PPL的parallel_for函數,如代碼5所示,我們傳給前者的extent對象代替了我們傳給後者的起止索引值。
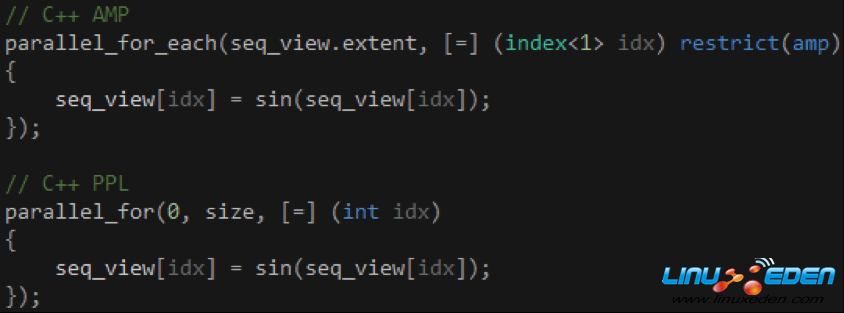
代碼 5
那麼,Kernel右邊的restrict(amp)修飾符又是怎麼一回事呢?Kernel最終是在GPU上運行的,不管以什麼樣的形式,restrict(amp)修飾符正是用來告訴編譯器這點的。當編譯器看到restrict(amp)修飾符時,它會檢查Kernel是否使用了不支持的語言特性,如果有,編譯過程中止,並列出錯誤,否則,Kernel會被編譯成HLSL,並交給DirectCompute運行。Kernel可以調用其他函數,但這些函數必須添加restrict(amp)修飾符,比如代碼4的sin函數。
計算完畢之後,我們可以通過一個for循環輸出array_view對象的數據,如代碼6所示。當我們在CPU上首次通過索引器訪問array_view對象時,它會把數據從顯存複製回系統內存,這個過程是自動的,無需我們干預。
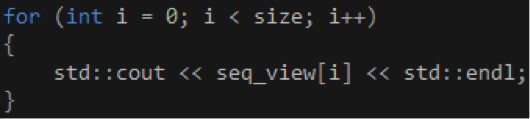
代碼 6
哇,不知不覺已經講了這麼多,其實,使用C++ AMP一般只涉及到以下三步:
上一節我們通過一個簡單的示例了解C++ AMP的使用步驟,接下來我們將會通過另一個示例深入了解array_view、extent和index在二維場景里的用法。
假設我們現在要計算兩個100 x 100的矩陣之和,首先定義矩陣的行和列,然後通過create_matrix函數創建兩個vector對象,接著創建一個vector對象用於存放矩陣之和,如代碼7所示。
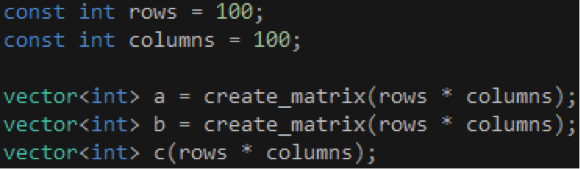
代碼 7
create_matrix函數的實現很簡單,它接受矩陣的總容量(行和列之積)作為參數,然後創建並返回一個包含100以內的隨機數的vector對象,如代碼8所示。
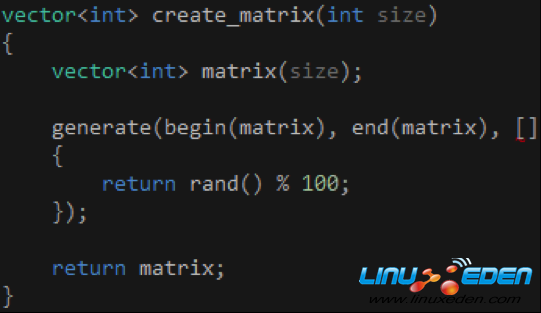
代碼 8
值得提醒的是,當create_matrix函數執行“return matrix;”時,會把vector對象拷貝到一個臨時對象,並把這個臨時對象返回給調用方,而原來的vector對象則會因為超出作用域而自動銷毀,但我們可以通過編譯器的Named Return Value Optimization對此進行優化,因此不必擔心按值返回會帶來性能問題。
雖然我們通過行和列等二維概念定義矩陣,但它的實現是通過vector對象模擬的,因此在使用的時候我們需要做一下索引變換,矩陣的第m行第n列元素對應的vector對象的索引是m * columns + n(m、n均從0開始計算)。假設我們要用vector對象模擬一個3 x 3的矩陣,如圖1所示,那麼,要訪問矩陣的第2行第0列元素,應該使用索引6(2 * 3 + 0)訪問vector對象。
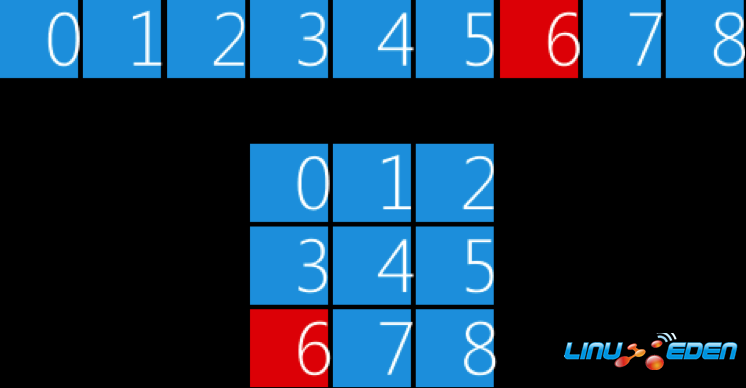
圖 1
接下來,我們需要創建三個array_view對象,分別包裝前面創建的三個vector對象,創建的時候先指定行的大小,再指定列的大小,如代碼9所示。

代碼 9
因為我們創建的是二維的array_view對象,所以我們可以直接使用二維索引訪問矩陣的元素,而不必像前面那樣計算對應的索引。還是以3 x 3的矩陣為例,如圖2所示,vector對象會被分成三段,每段包含三個元素,第一段對應array_view對象的第一行,第二段對應第二行,如此類推。如果我們想訪問矩陣的第2行第0列的元素,可以直接使用索引 (2, 0) 訪問array_view對象,這個索引對應vector對象的索引6。
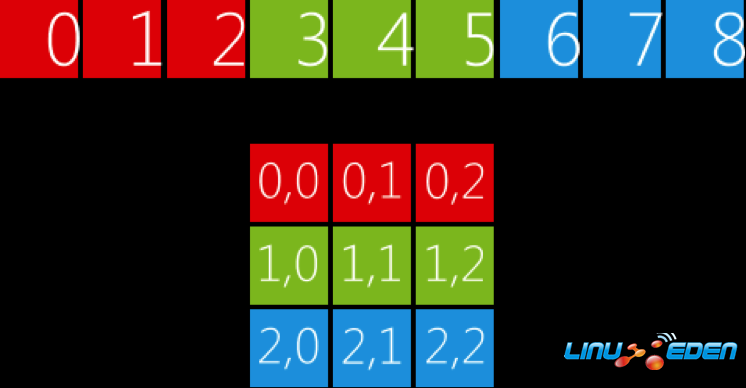
圖 2
考慮到第一、二個array_view對象的數據流動方向是從系統內存到顯存,我們可以把它們的第一個類型參數改為const int,如代碼10所示,表示它們在Kernel里是只讀的,不會對它包裝的vector對象產生任何影響。至於第三個array_view對象,由於它只是用來輸出計算結果,我們可以在調用parallel_for_each函數之前調用array_view對象的discard_data成員函數,表明我們對它包裝的vector對象的數據不感興趣,不必把它們從系統內存複製到顯存。
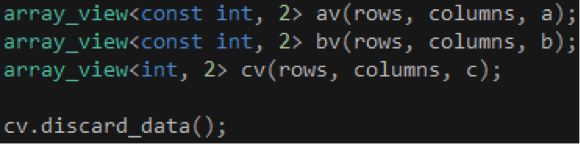
代碼 10
有了這些準備,我們就可以著手編寫Kernel了,如代碼11所示。我們把第三個array_view對象的extent傳給parallel_for_each函數,由於這個矩陣是100 x 100的,parallel_for_each函數會創建10,000個GPU線程,每個GPU線程計算這個矩陣的一個元素。由於我們訪問的array_view對象是二維的,索引的類型也要改為相應的index<2>。

代碼 11
看到這裡,你可能會問,GPU真能創建這麼多個線程嗎?這取決於具體的GPU,比如說,NVIDIA GTX 690有16個多處理器(Kepler架構,每個多處理器有192個CUDA核),每個多處理器的最大線程數是2048,因此可以同時容納最多32,768個線程;而NVIDIA GTX 560 SE擁有9個多處理器(Fermi架構,每個多處理器有32個CUDA核),每個多處理器的最大線程數是1536,因此可以同時容納最多13,824個線程。
計算完畢之後,我們可以在CPU上通過索引器訪問計算結果,代碼12向控制台輸出結果矩陣的第14行12列元素。

代碼 12
掌握了C++ AMP的基本用法之後,我們很自然就想知道parallel_for_each函數會否阻塞當前CPU線程。parallel_for_each函數本身是同步的,它負責發起Kernel的運行,但不會等到Kernel的運行結束才返回。以代碼13為例,當parallel_for_each函數返回時,即使Kernel的運行還沒結束,checkpoint 1位置的代碼也會照常運行,從這個角度來看,parallel_for_each函數是非同步的。但是,當我們通過array_view對象訪問計算結果時,如果Kernel的運行還沒結束,checkpoint 2位置的代碼會卡住,直到Kernel的運行結束,array_view對象把數據從顯存複製到系統內存為止。
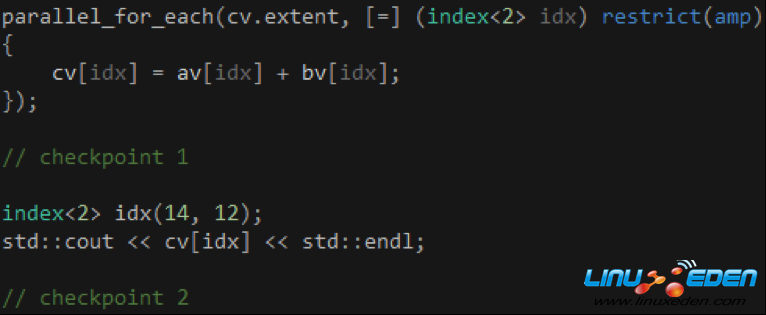
代碼 13
既然Kernel的運行是非同步的,我們很自然就會希望C++ AMP能夠提供類似C++ PPL的continuation。幸運的是,array_view對象提供一個synchronize_async成員函數,它返回一個concurrency::completion_future對象,我們可以通過這個對象的then成員函數實現continuation,如代碼14所示。事實上,這個then成員函數就是通過C++ PPL的task對象實現的。
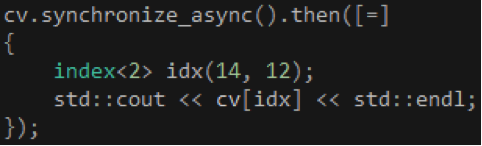
代碼 14
開發C++ AMP程序需要什麼條件?
你需要Visual Studio 2012以及一塊支持DirectX 11的顯卡,Visual C++ 2012 Express應該也可以,如果你想做GPU調試,你還需要Windows 8操作系統。運行C++ AMP程序需要Windows 7/Windows 8以及一塊支持DirectX 11的顯卡,部署的時候需要把C++ AMP的運行時(vcamp110.dll)放在程序可以找到的目錄里,或者在目標機器上安裝Visual C++ 2012 Redistributable Package。
C++ AMP是否支持其他語言?
C++ AMP只能在C++里使用,其他語言可以通過相關機制間接調用你的C++ AMP代碼:
C++ AMP是否支持其他平台?
目前C++ AMP只支持Windows平台,不過,微軟發布了C++ AMP開放標準,支持任何人在任何平台上實現它。如果你希望在其他平台上利用GPU做并行計算,你可以考慮其他技術,比如NVIDIA的CUDA(只支持NVIDIA的顯卡),或者OpenCL,它們都支持多個平台。
能否推薦一些C++ AMP的學習資料?
目前還沒有C++ AMP的書,Kate Gregory和Ade Miller正在寫一本關於C++ AMP的書,希望很快能夠看到它。下面推薦一些在線學習資料:
[火星人 ] 遇見C++ AMP:在GPU上做并行計算已經有565次圍觀
