spaCy 是一個 Python 和 CPython 的 NLP 自然語言文本處理庫。spaCy 2.2 自然語言處理庫更精簡,更乾淨,更方便用戶使用,除了用於培訓、評估和序列化的新模型包和特性之外,還進行了大量的 bug 修復,改進了調試和錯誤處理,並大大減少了磁碟上庫的大小。
新模型與數據增強
spaCy v2.2 提供了經過再培訓的統計模型,其中包括修復錯誤和改進大小寫文本的性能。與其他統計模型一樣,spaCy 的模型可能對培訓數據和正在處理的數據之間的差異非常敏感。
用於訓練的新 CLI 功能
spaCy v2.2 包括對培訓和數據開發工作流的幾個可用性改進,特別是對於文本分類。改進了錯誤消息,更新了文檔,並使評估指標更加詳細。例如,評估現在默認提供每一實體類型和每文本類別的準確性統計信息。最有用的改進之一是在 spaCy train 命令行介面中集成了對文本分類器的支持。現在可以編寫如下命令,就像在訓練解析器、實體識別器或標記器時一樣:
$ python -m spacy train en /output /train /dev --pipeline textcat
--textcat-arch simple_cnn --textcat-multilabel
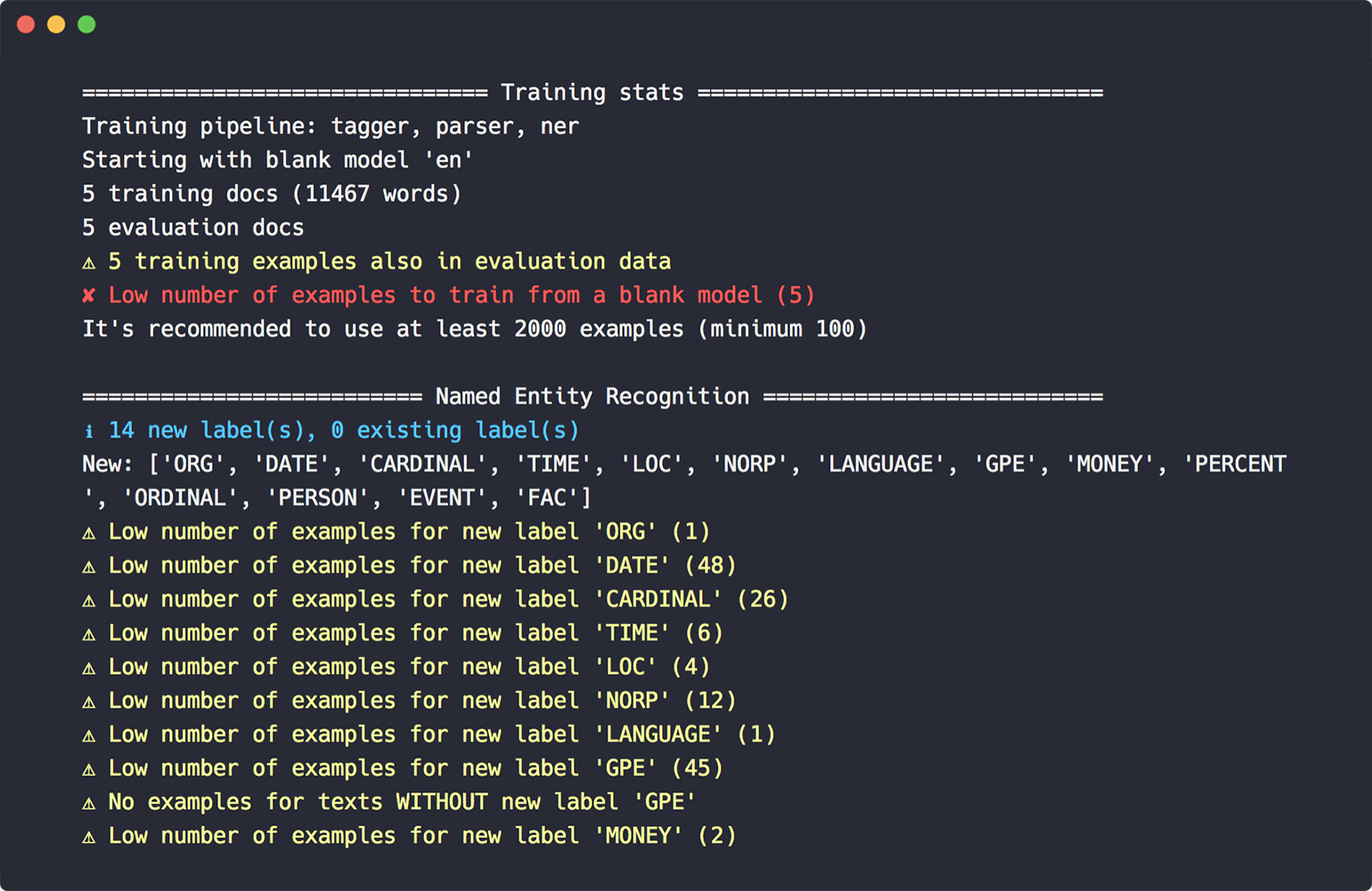
為了使培訓更加容易,還引入了一個新的 debug-data 命令,以驗證你的培訓和開發數據,獲取有用的統計數據,並發現諸如無效的實體註釋、循環依賴關係、低數據標籤等問題。
更小的磁碟佔有,更好的語言資源處理
隨著 spaCy 支持更多的語言,磁碟佔用也在上升,特別是當添加了對基於查找的 lemmatization 表的支持時,這些表作為 Python 文件存儲,在某些情況下變得相當大。此版已經將這些查找錶轉換為壓縮的 JSON,並將它們移到一個單獨的包 spacy-look-data 中。
用於高效序列化的 DocBin
高效的序列化對於大規模文本處理是非常重要的,對於許多用例,一種很好的方法是使用 Doc.to_Array 方法將 spaCy Doc 對象序列化為 numpy 數組。然而,這種方法確實失去了一些信息。
新的 DocBin 類幫助你高效地序列化和反序列化 Doc 對象的集合,自動處理許多細節。下面是一個基本用法示例:
import spacy
from spacy.tokens import DocBin
doc_bin = DocBin(attrs=["LEMMA", "ENT_IOB", "ENT_TYPE"], store_user_data=True)
texts = ["Some text", "Lots of texts...", "..."]
nlp = spacy.load("en_core_web_sm")
for doc in nlp.pipe(texts):
doc_bin.add(doc)
bytes_data = docbin.to_bytes()
# Deserialize later, e.g. in a new process
nlp = spacy.blank("en")
doc_bin = DocBin().from_bytes(bytes_data)
docs = list(doc_bin.get_docs(nlp.vocab))
Better Dutch NER with 20 categories
2.2 中引入新的數據集,這將對經過預先訓練的 Dutch NER 模型更加有用。然而,之前的評估是對半自動創建的維基百科數據進行的,這使得該模型更容易獲得高分。當在模型訓練管道中加入預訓練詞向量和支持 spaCy pretrain 命令時,模型的精度會進一步提高。
新的視頻系列
官方還提供了新的面向初學者的視頻教程系列,與數據科學講師 Vincent Warmerdam 合作。
更多詳情見發布說明:
[admin
]
來源:OsChina
連結:https://www.oschina.net/news/110351/spacy-2-2-released
spaCy 2.2 發布,NLP 自然語言文本處理庫已經有356次圍觀
