最近在工作上用到Python的pandas庫來處理excel文件,遇到列轉行的問題。找了一番資料後成功了,記錄一下。
1. 如果需要爆炸的只有一列:
df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[1]: A B 0 1 [1, 2] 1 2 [1, 2]
如果要爆炸B這一列,可以直接用explode方法(前提是你的pandas的版本要高於或等於0.25)
df.explode('B') A B 0 1 1 1 1 2 2 2 1 3 2 2
2. 如果需要爆炸的有2列及以上
df=pd.DataFrame({'A':[1,2],'B':[[1,2],[3,4]],'C':[[1,2],[3,4]]}) df Out[592]: A B C 0 1 [1, 2] [1, 2] 1 2 [3, 4] [3, 4]
則可以用寫一個方法,如下代碼:
def unnesting(df, explode): idx = df.index.repeat(df[explode[0]].str.len()) df1 = pd.concat([ pd.DataFrame({x: np.concatenate(df[x].values)}) for x in explode], axis=1) df1.index = idx return df1.join(df.drop(explode, 1), how='left') unnesting(df,['B','C']) Out[2]: B C A 0 1 1 1 0 2 2 1 1 3 3 2 1 4 4 2
補充知識:pandas:一列分解成多列 series.str.split(',',expand=True);pyspark 一列分解成多列
源shuju
question_id id 0 17576 70391,70394 1 17576 70391,70392,70393,70394 2 17576 70391,70392 3 40430 155032,155033,155034 4 40430 155032,155033,155034,155035 5 40430 155033,155034,155035 6 40430 155032,155035 7 40430 155034,155035 8 40430 155032,155034 9 40430 155032,155034,155035 10 40430 155033,155034 11 40430 155032,155033 12 40430 155033,155035 13 40430 155032,155033,155035
pandas solution
df.join(df['id'].str.split(',',expand=True)
result
0 1 2 3 0 70391 70394 None None 1 70391 70392 70393 70394 2 70391 70392 None None 3 155032 155033 155034 None 4 155032 155033 155034 155035 5 155033 155034 155035 None 6 155032 155035 None None 7 155034 155035 None None 8 155032 155034 None None 9 155032 155034 155035 None 10 155033 155034 None None 11 155032 155033 None None 12 155033 155035 None None 13 155032 155033 155035 None
#注意expand=True
df.join(df['id'].str.split(',',expand=True))
question_id id 0 1 2 3 0 17576 70391,70394 70391 70394 None None 1 17576 70391,70392,70393,70394 70391 70392 70393 70394 2 17576 70391,70392 70391 70392 None None 3 40430 155032,155033,155034 155032 155033 155034 None 4 40430 155032,155033,155034,155035 155032 155033 155034 155035 5 40430 155033,155034,155035 155033 155034 155035 None 6 40430 155032,155035 155032 155035 None None 7 40430 155034,155035 155034 155035 None None 8 40430 155032,155034 155032 155034 None None 9 40430 155032,155034,155035 155032 155034 155035 None 10 40430 155033,155034 155033 155034 None None 11 40430 155032,155033 155032 155033 None None 12 40430 155033,155035 155033 155035 None None 13 40430 155032,155033,155035 155032 155033 155035 None
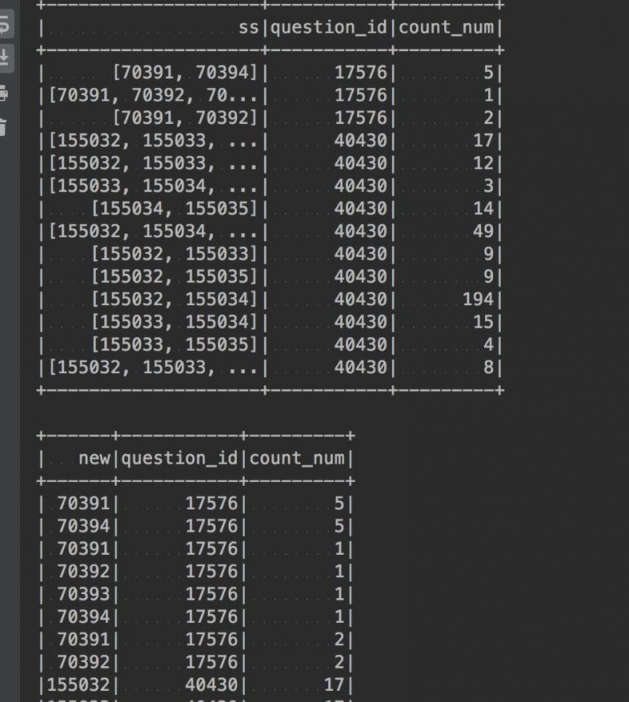
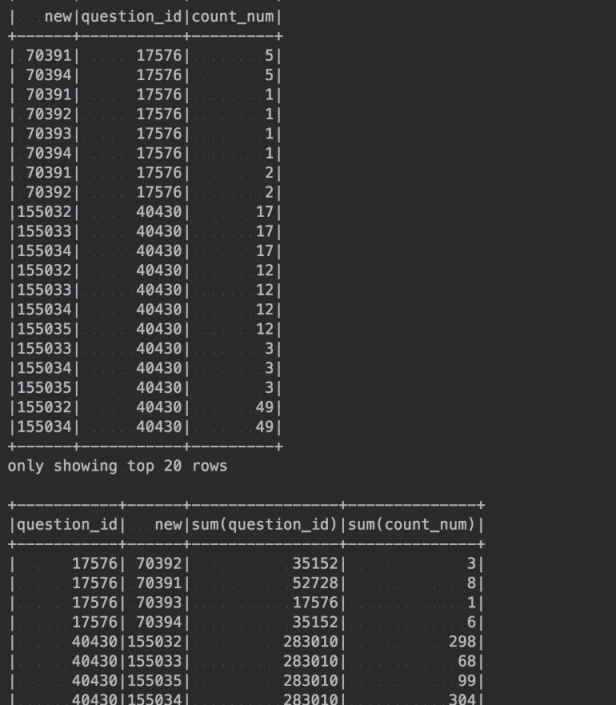
pyspark solution tdf=df.select(F.split(df.id,',').alias('ss'),'question_id','count_num') tdf.sort('question_id').show() res=tdf.select(F.explode(tdf.ss).alias('new'),'question_id','count_num') res.sort('question_id').show() res.groupBy('question_id','new').sum().sort('question_id').show()
result
[e36605 ] Python pandas 列轉行操作詳解(類似hive中explode方法)已經有253次圍觀
