如下所示:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
subset考慮重複發生在哪一列,默認考慮所有列,就是在任何一列上出現重複都算作是重複數據
keep 包含三個參數first, last, False,first是指,保留搜索到的第一個重複數據,之後的都刪除;last是指,保留搜索到的最後一個重複數據,之前的搜索到的重複數據都刪除,False是指,把所有搜索到的重複數據都刪除,一個都不保留,即如果有兩行數據重複,把兩行數據都刪除,而不是保留其中一行。默認參數是first。
補充知識:python3刪除數據重複值,只保留第一項。drop_duplicates()函數使用介紹
原始數據如下:
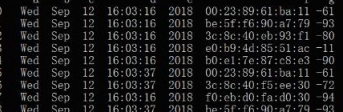
f 列的前3個數據都有重複項,現在要將重複值刪去,只保留第一項或最後一項。
使用drop_duplicates()
drop_duplicates(self, subset=None, keep='first', inplace=False)
subset :如['a']代表a列中的重複值全部被刪除
keep:保留第一個值,參數為first,last
inplace:是否替換原來的df,默認為False
import pandas as pd data = pd.read_table("C:/Users/xujinhua/Desktop/aa/a.txt",header=None, names=['a','b','c','d','e','f','g']) #讀取文件數據,並將列命名為abcdef data.drop_duplicates(subset='f', keep='first', inplace=True) print(data)
結果:
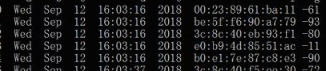
可以看到 f 列中的重複值都被刪除,且保留了第一項
[qp18502452 ] pandas.DataFrame.drop已經有398次圍觀
