如果你的電腦內存較小那麼想在本地做一些事情是很有侷限性的(哭喪臉),比如想拿一個kaggle上面的競賽來練練手,你會發現多數訓練數據集都是大幾G或者幾十G的,自己那小破電腦根本跑不起來。行,你有8000w條樣本你牛逼,我就取400w條出來跑跑總行了吧(狡滑臉)。
下圖是2015年kaggle上一個CTR預估比賽的數據集:

看到train了吧,原始數據集6個G,特徵工程後得多大?那我就取400w出來train。為了節省時間和完整介紹分批讀入數據的功能,這裡以test數據集為例演示。其實就是使用pandas讀取數據集時加入參數chunksize。
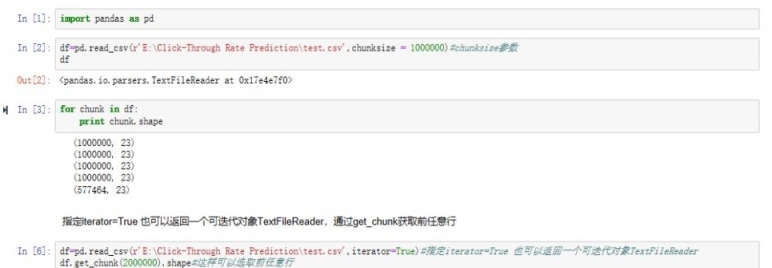
可以通過設置chunksize大小分批讀入,也可以設置iterator=True後通過get_chunk選取任意行。
當然將分批讀入的數據合併後就是整個數據集了。
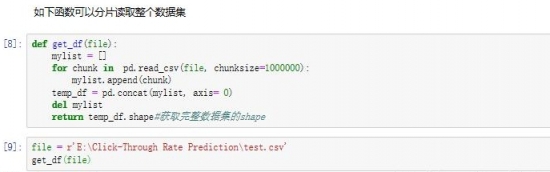
ok了!
補充知識:用Pandas 處理大數據的3種超級方法
易上手, 文檔豐富的Pandas 已經成為時下最火的數據處理庫。此外,Pandas數據處理能力也一流。
其實無論你使用什麼庫,大量的數據處理起來往往回遇到新的挑戰。
數據處理時,往往會遇到沒有足夠內存(RAM)這個硬件問題。 企業往往需要能夠存夠數百, 乃至數千 的GB 數據。
即便你的計算機恰好有足夠的內存來存儲這些數據, 但是讀取數據到硬盤依舊非常耗時。
別擔心! Pandas 數據庫會幫我們擺脫這種困境。 這篇文章包含3種方法來減少數據大小,並且加快數據讀取速度。 我用這些方法,把超過100GB 的數據, 壓縮到了64GB 甚至32GB 的內存大小。
快來看看這三個妙招吧。
數據分塊
csv 格式是一種易儲存, 易更改並且用戶易讀取的格式。 pandas 有read_csv ()方法來上傳數據,存儲為CSV 格式。當遇到CSV 文件過大,導致內存不足的問題該怎麼辦呢?試試強大的pandas 工具吧!我們先把整個文件拆分成小塊。這裡,我們把拆分的小塊稱為chunk。
一個chunk 就是我們數據的一個小組。 Chunk 的大小主要依據我們內存的大小,自行決定。
過程如下:
1.讀取一塊數據。
2.分析數據。
3.保存該塊數據的分析結果。
4.重複1-3步驟,直到所有chunk 分析完畢。
5.把所有的chunk 合併在一起。
我們可以通過read_csv()方法Chunksize來完成上述步驟。 Chunksize是指pandas 一次能讀取到多少行csv文件。這個當然也是建立在RAM 內存容量的基礎上。
假如我們認為數據呈現高斯分佈時, 我們可以在一個chunk 上, 進行數據處理和視覺化, 這樣會提高準確率。
當數據稍微複雜時, 例如呈現泊松分佈時, 我們最好能一塊塊篩選,然後把每一小塊整合在一起。 然後再進行分析。很多時候, 我們往往刪除太多的不相關列,或者刪除有值行。 我們可以在每個chunk 上,刪除不相關數據, 然後再把數據整合在一起,最後再進行數據分析。
代碼如下:
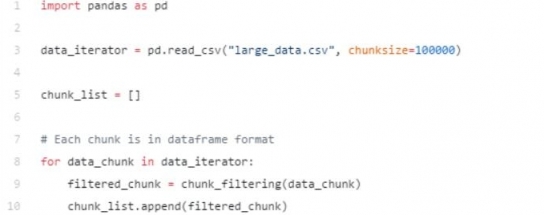
刪除數據
有時候, 我們一眼就能看到需要分析的列。事實上, 通常名字,賬號等列,我們是不做分析的。
讀取數據前, 先跳過這些無用的列,可以幫我們節省很多內存。 Pandas 可以允許我們選擇想要讀取的列。

把包含無用信息的列刪除掉, 往往給我們節省了大量內存。
此外,我們還可以把有缺失值的行,或者是包含“NA” 的行刪除掉。 通過dropna()方法可以實現:

有幾個非常有用的參數,可以傳給dropna():
how: 可選項:“any”(該行的任意一列如果出現”NA”, 刪除該行)
“all” (只有某行所有數數據全部是”NA” 時才刪除)
thresh: 設定某行最多包含多少個NA 時,才進行刪除
subset: 選定某個子集,進行NA 查找
可以通過這些參數, 尤其是thresh 和 subset 兩個參數可以決定某行是否被刪除掉。
Pandas 在讀取信息的時候,無法刪除列。但是我們可以在每個chunk 上,進行上述操作。
為列設定不同的數據類型
數據科學家新手往往不會對數據類型考慮太多。 當處理數據越來越多時, 就非常有必要考慮數據類型了。
行業常用的解決方法是從數據文件中,讀取數據, 然後一列列設置數據類型。 但當數據量非常大時, 我們往往擔心內存空間不夠用。
在CSV 文件中,例如某列是浮點數, 它往往會佔據更多的存儲空間。 例如, 當我們下載數據來預測股票信息時, 價格往往以32位浮點數形式存儲。
但是,我們真的需要32位浮點數碼? 大多數情況下, 股票價格以小數點後保留兩位數據進行交易。 即便我們想看到更精確的數據, 16位浮點數已經足夠了。
我們往往會在讀取數據的時候, 設置數據類型,而不是保留數據原類型。 那樣的話,會浪費掉部分內存。
通過read_csv() 中設置dtype參數來完成數據類型設置。還可以設置字典類型,設置該列是鍵, 設置某列是字典的值。
請看下面的pandas 例子:

文章到這裡結束了! 希望上述三個方法可以幫你節省時間和內存。
[bom485332 ] pandas分批讀取大數據集教程已經有485次圍觀
