大致介紹
在python爬蟲爬取某些網站的驗證碼的時候可能會遇到驗證碼識別的問題,現在的驗證碼大多分為四類:
1、計算驗證碼
2、滑塊驗證碼
3、識圖驗證碼
4、語音驗證碼
這篇博客主要寫的就是識圖驗證碼,識別的是簡單的驗證碼,要想讓識別率更高,識別的更加準確就需要花很多的精力去訓練自己的字體庫。
識別驗證碼通常是這幾個步驟:
1、灰度處理
2、二值化
3、去除邊框(如果有的話)
4、降噪
5、切割字符或者傾斜度矯正
6、訓練字體庫
7、識別
這6個步驟中前三個步驟是基本的,4或者5可根據實際情況選擇是否需要,並不一定切割驗證碼,識別率就會上升很多有時候還會下降
這篇博客不涉及訓練字體庫的內容,請自行搜索。同樣也不講解基礎的語法。
用到的幾個主要的python庫: Pillow(python圖像處理庫)、OpenCV(高級圖像處理庫)、pytesseract(識別庫)
灰度處理&二值化
灰度處理,就是把彩色的驗證碼圖片轉為灰色的圖片。
二值化,是將圖片處理為只有黑白兩色的圖片,利於後面的圖像處理和識別
在OpenCV中有現成的方法可以進行灰度處理和二值化,處理後的效果:
代碼:
# 自適應閥值二值化 def _get_dynamic_binary_image(filedir, img_name): filename = './out_img/' + img_name.split('.')[0] + '-binary.jpg' img_name = filedir + '/' + img_name print('.....' + img_name) im = cv2.imread(img_name) im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) #灰值化 # 二值化 th1 = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1) cv2.imwrite(filename,th1) return th1
去除邊框
如果驗證碼有邊框,那我們就需要去除邊框,去除邊框就是遍歷像素點,找到四個邊框上的所有點,把他們都改為白色,我這裡邊框是兩個像素寬
注意:在用OpenCV時,圖片的矩陣點是反的,就是長和寬是顛倒的
代碼:
# 去除邊框 def clear_border(img,img_name): filename = './out_img/' + img_name.split('.')[0] + '-clearBorder.jpg' h, w = img.shape[:2] for y in range(0, w): for x in range(0, h): if y < 2 or y > w - 2: img[x, y] = 255 if x < 2 or x > h -2: img[x, y] = 255 cv2.imwrite(filename,img) return img
降噪
降噪是驗證碼處理中比較重要的一個步驟,我這裡使用了點降噪和線降噪

線降噪的思路就是檢測這個點相鄰的四個點(圖中標出的綠色點),判斷這四個點中是白點的個數,如果有兩個以上的白色像素點,那麼就認為這個點是白色的,從而去除整個干擾線,但是這種方法是有限度的,如果幹擾線特別粗就沒有辦法去除,只能去除細的干擾線
代碼:
# 干擾線降噪 def interference_line(img, img_name): filename = './out_img/' + img_name.split('.')[0] + '-interferenceline.jpg' h, w = img.shape[:2] # !!!opencv矩陣點是反的 # img[1,2] 1:圖片的高度,2:圖片的寬度 for y in range(1, w - 1): for x in range(1, h - 1): count = 0 if img[x, y - 1] > 245: count = count + 1 if img[x, y + 1] > 245: count = count + 1 if img[x - 1, y] > 245: count = count + 1 if img[x + 1, y] > 245: count = count + 1 if count > 2: img[x, y] = 255 cv2.imwrite(filename,img) return img
點降噪的思路和線降噪的差不多,只是會針對不同的位置檢測的點不一樣,註釋寫的很清楚了
代碼:
# 點降噪 def interference_point(img,img_name, x = 0, y = 0): """ 9鄰域框,以當前點為中心的田字框,黑點個數 :param x: :param y: :return: """ filename = './out_img/' + img_name.split('.')[0] + '-interferencePoint.jpg' # todo 判斷圖片的長寬度下限 cur_pixel = img[x,y]# 當前像素點的值 height,width = img.shape[:2] for y in range(0, width - 1): for x in range(0, height - 1): if y == 0: # 第一行 if x == 0: # 左上頂點,4鄰域 # 中心點旁邊3個點 sum = int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 2 * 245: img[x, y] = 0 elif x == height - 1: # 右上頂點 sum = int(cur_pixel) + int(img[x, y + 1]) + int(img[x - 1, y]) + int(img[x - 1, y + 1]) if sum <= 2 * 245: img[x, y] = 0 else: # 最上非頂點,6鄰域 sum = int(img[x - 1, y]) + int(img[x - 1, y + 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 elif y == width - 1: # 最下面一行 if x == 0: # 左下頂點 # 中心點旁邊3個點 sum = int(cur_pixel) + int(img[x + 1, y]) + int(img[x + 1, y - 1]) + int(img[x, y - 1]) if sum <= 2 * 245: img[x, y] = 0 elif x == height - 1: # 右下頂點 sum = int(cur_pixel) + int(img[x, y - 1]) + int(img[x - 1, y]) + int(img[x - 1, y - 1]) if sum <= 2 * 245: img[x, y] = 0 else: # 最下非頂點,6鄰域 sum = int(cur_pixel) + int(img[x - 1, y]) + int(img[x + 1, y]) + int(img[x, y - 1]) + int(img[x - 1, y - 1]) + int(img[x + 1, y - 1]) if sum <= 3 * 245: img[x, y] = 0 else: # y不在邊界 if x == 0: # 左邊非頂點 sum = int(img[x, y - 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y - 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 elif x == height - 1: # 右邊非頂點 sum = int(img[x, y - 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x - 1, y - 1]) + int(img[x - 1, y]) + int(img[x - 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 else: # 具備9領域條件的 sum = int(img[x - 1, y - 1]) + int(img[x - 1, y]) + int(img[x - 1, y + 1]) + int(img[x, y - 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y - 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 4 * 245: img[x, y] = 0 cv2.imwrite(filename,img) return img
效果:

其實到了這一步,這些字符就可以識別了,沒必要進行字符切割了,現在這三種類型的驗證碼識別率已經達到50%以上了
字符切割
字符切割通常用於驗證碼中有粘連的字符,粘連的字符不好識別,所以我們需要將粘連的字符切割為單個的字符,在進行識別
字符切割的思路就是找到一個黑色的點,然後在遍歷與他相鄰的黑色的點,直到遍歷完所有的連接起來的黑色的點,找出這些點中的最高的點、最低的點、最右邊的點、最左邊的點,記錄下這四個點,認為這是一個字符,然後在向後遍歷點,直至找到黑色的點,繼續以上的步驟。最後通過每個字符的四個點進行切割
圖中紅色的點就是代碼執行完後,標識出的每個字符的四個點,然後就會根據這四個點進行切割(圖中畫的有些誤差,懂就好)
但是也可以看到,m2是粘連的,代碼認為他是一個字符,所以我們需要對每個字符的寬度進行檢測,如果他的寬度過寬,我們就認為他是兩個粘連在一起的字符,並將它在從中間切割
確定每個字符的四個點代碼:
def cfs(im,x_fd,y_fd): '''用隊列和集合記錄遍歷過的像素座標代替單純遞歸以解決cfs訪問過深問題 ''' # print('**********') xaxis=[] yaxis=[] visited =set() q = Queue() q.put((x_fd, y_fd)) visited.add((x_fd, y_fd)) offsets=[(1, 0), (0, 1), (-1, 0), (0, -1)]#四鄰域 while not q.empty(): x,y=q.get() for xoffset,yoffset in offsets: x_neighbor,y_neighbor = x+xoffset,y+yoffset if (x_neighbor,y_neighbor) in (visited): continue # 已經訪問過了 visited.add((x_neighbor, y_neighbor)) try: if im[x_neighbor, y_neighbor] == 0: xaxis.append(x_neighbor) yaxis.append(y_neighbor) q.put((x_neighbor,y_neighbor)) except IndexError: pass # print(xaxis) if (len(xaxis) == 0 | len(yaxis) == 0): xmax = x_fd + 1 xmin = x_fd ymax = y_fd + 1 ymin = y_fd else: xmax = max(xaxis) xmin = min(xaxis) ymax = max(yaxis) ymin = min(yaxis) #ymin,ymax=sort(yaxis) return ymax,ymin,xmax,xmin def detectFgPix(im,xmax): '''搜索區塊起點 ''' h,w = im.shape[:2] for y_fd in range(xmax+1,w): for x_fd in range(h): if im[x_fd,y_fd] == 0: return x_fd,y_fd def CFS(im): '''切割字符位置 ''' zoneL=[]#各區塊長度L列表 zoneWB=[]#各區塊的X軸[起始,終點]列表 zoneHB=[]#各區塊的Y軸[起始,終點]列表 xmax=0#上一區塊結束黑點橫座標,這裡是初始化 for i in range(10): try: x_fd,y_fd = detectFgPix(im,xmax) # print(y_fd,x_fd) xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd) L = xmax - xmin H = ymax - ymin zoneL.append(L) zoneWB.append([xmin,xmax]) zoneHB.append([ymin,ymax]) except TypeError: return zoneL,zoneWB,zoneHB return zoneL,zoneWB,zoneHB
分割粘連字符代碼:
# 切割的位置 im_position = CFS(im) maxL = max(im_position[0]) minL = min(im_position[0]) # 如果有粘連字符,如果一個字符的長度過長就認為是粘連字符,並從中間進行切割 if(maxL > minL + minL * 0.7): maxL_index = im_position[0].index(maxL) minL_index = im_position[0].index(minL) # 設置字符的寬度 im_position[0][maxL_index] = maxL // 2 im_position[0].insert(maxL_index + 1, maxL // 2) # 設置字符X軸[起始,終點]位置 im_position[1][maxL_index][1] = im_position[1][maxL_index][0] + maxL // 2 im_position[1].insert(maxL_index + 1, [im_position[1][maxL_index][1] + 1, im_position[1][maxL_index][1] + 1 + maxL // 2]) # 設置字符的Y軸[起始,終點]位置 im_position[2].insert(maxL_index + 1, im_position[2][maxL_index]) # 切割字符,要想切得好就得配置參數,通常 1 or 2 就可以 cutting_img(im,im_position,img_name,1,1)
切割粘連字符代碼:
def cutting_img(im,im_position,img,xoffset = 1,yoffset = 1): filename = './out_img/' + img.split('.')[0] # 識別出的字符個數 im_number = len(im_position[1]) # 切割字符 for i in range(im_number): im_start_X = im_position[1][i][0] - xoffset im_end_X = im_position[1][i][1] + xoffset im_start_Y = im_position[2][i][0] - yoffset im_end_Y = im_position[2][i][1] + yoffset cropped = im[im_start_Y:im_end_Y, im_start_X:im_end_X] cv2.imwrite(filename + '-cutting-' + str(i) + '.jpg',cropped)
識別
識別用的是typesseract庫,主要識別一行字符和單個字符時的參數設置,識別中英文的參數設置,代碼很簡單就一行,我這裡大多是filter文件的操作
代碼:
# 識別驗證碼 cutting_img_num = 0 for file in os.listdir('./out_img'): str_img = '' if fnmatch(file, '%s-cutting-*.jpg' % img_name.split('.')[0]): cutting_img_num += 1 for i in range(cutting_img_num): try: file = './out_img/%s-cutting-%s.jpg' % (img_name.split('.')[0], i) # 識別字符 str_img = str_img + image_to_string(Image.open(file),lang = 'eng', config='-psm 10') #單個字符是10,一行文本是7 except Exception as err: pass print('切圖:%s' % cutting_img_num) print('識別為:%s' % str_img)
最後這種粘連字符的識別率是在30%左右,而且這種只是處理兩個字符粘連,如果有兩個以上的字符粘連還不能識別,但是根據字符寬度判別的話也不難,有興趣的可以試一下
無需切割字符識別的效果:

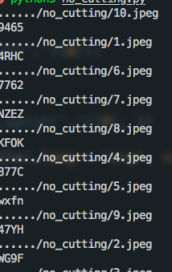
需要切割字符的識別效果:

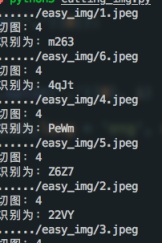
這種只是能夠識別簡單驗證碼,複雜的驗證碼還要靠大家了
參考資料:
1、https://www.jb51.net/article/141621.htm
本來參考了挺多的資料,但是時間長了就找不到了,如果有人發現了,可以告訴我,我再添加
使用方法:
1、將要識別的驗證碼圖片放入與腳本同級的img文件夾中,創建out_img文件夾
2、python3 filename
3、二值化、降噪等各個階段的圖片將存儲在out_img文件夾中,最終識別結果會打印到屏幕上
最後附上源碼(帶切割,不想要切割的就自己修改吧):
from PIL import Image from pytesseract import * from fnmatch import fnmatch from queue import Queue import matplotlib.pyplot as plt import cv2 import time import os def clear_border(img,img_name): '''去除邊框 ''' filename = './out_img/' + img_name.split('.')[0] + '-clearBorder.jpg' h, w = img.shape[:2] for y in range(0, w): for x in range(0, h): # if y ==0 or y == w -1 or y == w - 2: if y < 4 or y > w -4: img[x, y] = 255 # if x == 0 or x == h - 1 or x == h - 2: if x < 4 or x > h - 4: img[x, y] = 255 cv2.imwrite(filename,img) return img def interference_line(img, img_name): ''' 干擾線降噪 ''' filename = './out_img/' + img_name.split('.')[0] + '-interferenceline.jpg' h, w = img.shape[:2] # !!!opencv矩陣點是反的 # img[1,2] 1:圖片的高度,2:圖片的寬度 for y in range(1, w - 1): for x in range(1, h - 1): count = 0 if img[x, y - 1] > 245: count = count + 1 if img[x, y + 1] > 245: count = count + 1 if img[x - 1, y] > 245: count = count + 1 if img[x + 1, y] > 245: count = count + 1 if count > 2: img[x, y] = 255 cv2.imwrite(filename,img) return img def interference_point(img,img_name, x = 0, y = 0): """點降噪 9鄰域框,以當前點為中心的田字框,黑點個數 :param x: :param y: :return: """ filename = './out_img/' + img_name.split('.')[0] + '-interferencePoint.jpg' # todo 判斷圖片的長寬度下限 cur_pixel = img[x,y]# 當前像素點的值 height,width = img.shape[:2] for y in range(0, width - 1): for x in range(0, height - 1): if y == 0: # 第一行 if x == 0: # 左上頂點,4鄰域 # 中心點旁邊3個點 sum = int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 2 * 245: img[x, y] = 0 elif x == height - 1: # 右上頂點 sum = int(cur_pixel) + int(img[x, y + 1]) + int(img[x - 1, y]) + int(img[x - 1, y + 1]) if sum <= 2 * 245: img[x, y] = 0 else: # 最上非頂點,6鄰域 sum = int(img[x - 1, y]) + int(img[x - 1, y + 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 elif y == width - 1: # 最下面一行 if x == 0: # 左下頂點 # 中心點旁邊3個點 sum = int(cur_pixel) + int(img[x + 1, y]) + int(img[x + 1, y - 1]) + int(img[x, y - 1]) if sum <= 2 * 245: img[x, y] = 0 elif x == height - 1: # 右下頂點 sum = int(cur_pixel) + int(img[x, y - 1]) + int(img[x - 1, y]) + int(img[x - 1, y - 1]) if sum <= 2 * 245: img[x, y] = 0 else: # 最下非頂點,6鄰域 sum = int(cur_pixel) + int(img[x - 1, y]) + int(img[x + 1, y]) + int(img[x, y - 1]) + int(img[x - 1, y - 1]) + int(img[x + 1, y - 1]) if sum <= 3 * 245: img[x, y] = 0 else: # y不在邊界 if x == 0: # 左邊非頂點 sum = int(img[x, y - 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y - 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 elif x == height - 1: # 右邊非頂點 sum = int(img[x, y - 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x - 1, y - 1]) + int(img[x - 1, y]) + int(img[x - 1, y + 1]) if sum <= 3 * 245: img[x, y] = 0 else: # 具備9領域條件的 sum = int(img[x - 1, y - 1]) + int(img[x - 1, y]) + int(img[x - 1, y + 1]) + int(img[x, y - 1]) + int(cur_pixel) + int(img[x, y + 1]) + int(img[x + 1, y - 1]) + int(img[x + 1, y]) + int(img[x + 1, y + 1]) if sum <= 4 * 245: img[x, y] = 0 cv2.imwrite(filename,img) return img def _get_dynamic_binary_image(filedir, img_name): ''' 自適應閥值二值化 ''' filename = './out_img/' + img_name.split('.')[0] + '-binary.jpg' img_name = filedir + '/' + img_name print('.....' + img_name) im = cv2.imread(img_name) im = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) th1 = cv2.adaptiveThreshold(im, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 1) cv2.imwrite(filename,th1) return th1 def _get_static_binary_image(img, threshold = 140): ''' 手動二值化 ''' img = Image.open(img) img = img.convert('L') pixdata = img.load() w, h = img.size for y in range(h): for x in range(w): if pixdata[x, y] < threshold: pixdata[x, y] = 0 else: pixdata[x, y] = 255 return img def cfs(im,x_fd,y_fd): '''用隊列和集合記錄遍歷過的像素座標代替單純遞歸以解決cfs訪問過深問題 ''' # print('**********') xaxis=[] yaxis=[] visited =set() q = Queue() q.put((x_fd, y_fd)) visited.add((x_fd, y_fd)) offsets=[(1, 0), (0, 1), (-1, 0), (0, -1)]#四鄰域 while not q.empty(): x,y=q.get() for xoffset,yoffset in offsets: x_neighbor,y_neighbor = x+xoffset,y+yoffset if (x_neighbor,y_neighbor) in (visited): continue # 已經訪問過了 visited.add((x_neighbor, y_neighbor)) try: if im[x_neighbor, y_neighbor] == 0: xaxis.append(x_neighbor) yaxis.append(y_neighbor) q.put((x_neighbor,y_neighbor)) except IndexError: pass # print(xaxis) if (len(xaxis) == 0 | len(yaxis) == 0): xmax = x_fd + 1 xmin = x_fd ymax = y_fd + 1 ymin = y_fd else: xmax = max(xaxis) xmin = min(xaxis) ymax = max(yaxis) ymin = min(yaxis) #ymin,ymax=sort(yaxis) return ymax,ymin,xmax,xmin def detectFgPix(im,xmax): '''搜索區塊起點 ''' h,w = im.shape[:2] for y_fd in range(xmax+1,w): for x_fd in range(h): if im[x_fd,y_fd] == 0: return x_fd,y_fd def CFS(im): '''切割字符位置 ''' zoneL=[]#各區塊長度L列表 zoneWB=[]#各區塊的X軸[起始,終點]列表 zoneHB=[]#各區塊的Y軸[起始,終點]列表 xmax=0#上一區塊結束黑點橫座標,這裡是初始化 for i in range(10): try: x_fd,y_fd = detectFgPix(im,xmax) # print(y_fd,x_fd) xmax,xmin,ymax,ymin=cfs(im,x_fd,y_fd) L = xmax - xmin H = ymax - ymin zoneL.append(L) zoneWB.append([xmin,xmax]) zoneHB.append([ymin,ymax]) except TypeError: return zoneL,zoneWB,zoneHB return zoneL,zoneWB,zoneHB def cutting_img(im,im_position,img,xoffset = 1,yoffset = 1): filename = './out_img/' + img.split('.')[0] # 識別出的字符個數 im_number = len(im_position[1]) # 切割字符 for i in range(im_number): im_start_X = im_position[1][i][0] - xoffset im_end_X = im_position[1][i][1] + xoffset im_start_Y = im_position[2][i][0] - yoffset im_end_Y = im_position[2][i][1] + yoffset cropped = im[im_start_Y:im_end_Y, im_start_X:im_end_X] cv2.imwrite(filename + '-cutting-' + str(i) + '.jpg',cropped) def main(): filedir = './easy_img' for file in os.listdir(filedir): if fnmatch(file, '*.jpeg'): img_name = file # 自適應閾值二值化 im = _get_dynamic_binary_image(filedir, img_name) # 去除邊框 im = clear_border(im,img_name) # 對圖片進行干擾線降噪 im = interference_line(im,img_name) # 對圖片進行點降噪 im = interference_point(im,img_name) # 切割的位置 im_position = CFS(im) maxL = max(im_position[0]) minL = min(im_position[0]) # 如果有粘連字符,如果一個字符的長度過長就認為是粘連字符,並從中間進行切割 if(maxL > minL + minL * 0.7): maxL_index = im_position[0].index(maxL) minL_index = im_position[0].index(minL) # 設置字符的寬度 im_position[0][maxL_index] = maxL // 2 im_position[0].insert(maxL_index + 1, maxL // 2) # 設置字符X軸[起始,終點]位置 im_position[1][maxL_index][1] = im_position[1][maxL_index][0] + maxL // 2 im_position[1].insert(maxL_index + 1, [im_position[1][maxL_index][1] + 1, im_position[1][maxL_index][1] + 1 + maxL // 2]) # 設置字符的Y軸[起始,終點]位置 im_position[2].insert(maxL_index + 1, im_position[2][maxL_index]) # 切割字符,要想切得好就得配置參數,通常 1 or 2 就可以 cutting_img(im,im_position,img_name,1,1) # 識別驗證碼 cutting_img_num = 0 for file in os.listdir('./out_img'): str_img = '' if fnmatch(file, '%s-cutting-*.jpg' % img_name.split('.')[0]): cutting_img_num += 1 for i in range(cutting_img_num): try: file = './out_img/%s-cutting-%s.jpg' % (img_name.split('.')[0], i) # 識別驗證碼 str_img = str_img + image_to_string(Image.open(file),lang = 'eng', config='-psm 10') #單個字符是10,一行文本是7 except Exception as err: pass print('切圖:%s' % cutting_img_num) print('識別為:%s' % str_img) if __name__ == '__main__': main()[e36605 ] Python實現驗證碼識別已經有272次圍觀
