Apache Flink 1.9.0 已經發布,Apache Flink 項目的目標是開發一個流處理系統,以統一和支持多種形式的實時和離線數據處理應用程序以及事件驅動的應用程序。
此版本包括批處理作業的批處理式恢復,以及新的基於閃爍的表 API 和 SQL 查詢引擎的預覽,還有狀態處理器 API 的可用性,它是最常見的請求特性之一,允許用戶使用 Flink DataSet 作業讀寫保存點。最後,包括一個重新設計的 WebUI 和 Flink 新的 Python Table API 的預覽以及它與 Apache Hive 生態系統的集成。
TableAPI & SQL
將 Table 模塊進行拆分(FLIP-32,FLIP 即 Flink Improvement Proposals,專門記錄一些對Flink 做較大修改的提議),對 Java 和 Scala 的 API 進行依賴梳理,並且提出了 Planner 介面以支持多種不同的 Planner 實現。Planner 將負責具體的優化和將 Table 作業翻譯成執行圖的工作,我們可以將原來的實現全部挪至 Flink Planner 中,然後把對接新架構的代碼放在 Blink Planner 里。
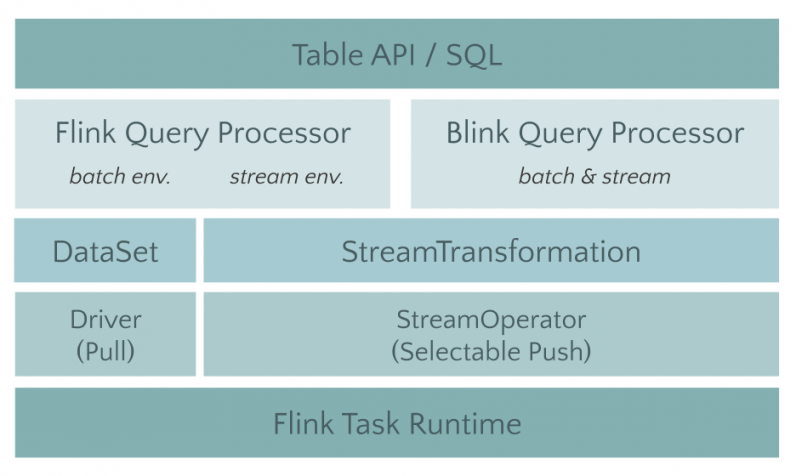
不僅讓 Table 模塊在經過拆分后更加清晰,更重要的是不影響老版本用戶的體驗。在 1.9 版本中,已經 merge 了大部分當初從 Blink 開源出來的 SQL 功能。
除了架構升級之外,Table 模塊在 1.9 版本還做了幾個相對比較大的重構和新功能,包括:
FLIP-37:重構 Table API 類型系統
FLIP-29:Table 增加面向多行多列操作的 API
FLINK-10232:初步的 SQL DDL 支持
FLIP-30:全新的統一的 Catalog API
FLIP-38:Table API 增加 Python 版本
批處理改進
Flink的批處理功能在 1.9 版本有了重大進步,首當其衝的是優化批處理的錯誤恢復代價:FLIP-1(Fine Grained Recovery from Task Failures),從這個 FLIP 的編號就可以看出,該優化其實很早就已經提出,1.9 版本終於有機會將 FLIP-1 中未完成的功能進行了收尾。
在新版本中,如果批處理作業有錯誤發生,那麼 Flink 首先會去計算這個錯誤的影響範圍,即 Failover Region。因為在批處理作業中,有些節點之間可以通過網路進行Pipeline 的數據傳輸,但其他一些節點可以通過 Blocking 的方式先把輸出數據存下來,然後下游再去讀取存儲的數據的方式進行數據傳輸。
如果運算元輸出的數據已經完整的進行了保存,那麼就沒有必要把這個運算元拉起重跑,這樣一來就可以把錯誤恢復控制在一個相對較小的範圍里。
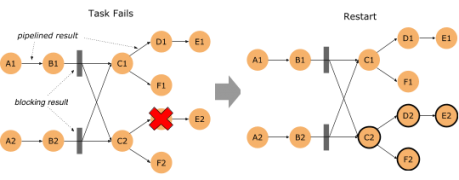
如果作業極端一點,在每一個需要Shuffle 的地方都進行數據落盤,那麼就和 MapReduce 以及 Spark 的行為類似了。只是 Flink 支持更高級的用法,你可以自行控制每種 Shuffle 是使用網路來直連,還是通過文件落盤來進行。
流處理改進
這個版本增加了一個非常實用的功能,即 FLIP-43(State Processor API)。Flink 的 State 數據的訪問,以及由 State 數據組成的 Savepoint 的訪問一直是社區用戶呼聲比較高的一個功能。
這次的 State Processor API 則提供了更加靈活的訪問手段,也能夠讓用戶完成一些比較黑科技的功能:
用戶可以使用這個 API 事先從其他外部系統讀取數據,把它們轉存為 Flink Savepoint 的格式,然後讓 Flink 作業從這個 Savepoint 啟動。這樣一來,就能避免很多冷啟動的問題。
使用 Flink 的批處理 API 直接分析State 的數據。State 數據一直以來對用戶是個黑盒,這裡面存儲的數據是對是錯,是否有異常,用戶都無從而知。有了這個 API 之後,用戶就可以像分析其他數據一樣,來對 State 數據進行分析。
臟數據訂正。假如有一條臟數據污染了你的 State,用戶還可以使用這個 API 對這樣的問題進行修復和訂正。
狀態遷移。當用戶修改了作業邏輯,想復用大部分原來作業的 State,但又希望做一些微調。那麼就可以使用這個 API 來完成相應的工作。
Hive 集成
在 1.9 版本中,通過 FLIP-30 提出的統一的 Catalog API 的幫助,目前 Flink 已經完整打通了對 Hive Meta Store 的訪問。同時,也增加了 Hive 的 Connector,目前已支持 CSV, Sequence File, Orc, Parquet 等格式。用戶只需要配置 HMS 的訪問方式,就可以使用 Flink 直接讀取 Hive 的表進行操作。在此基礎之上,Flink 還增加了對 Hive 自定義函數的兼容,像 UDF, UDTF和 UDAF,都可以直接運行在Flink SQL里。
Flink WebUI 修改
組件使用了最新的穩定版本的 Angular。
[admin
]
來源:OsChina
連結:https://www.oschina.net/news/109303/apache-flink-1-9-0-released
Apache Flink 1.9.0 發布,開源流處理框架已經有139次圍觀
